不均一分散#
import matplotlib.pyplot as plt
import lmdiag
import numpy as np
import pandas as pd
import statsmodels.formula.api as smf
import wooldridge
from seaborn import residplot
from statsmodels.stats.api import het_breuschpagan, het_white
from statsmodels.stats.outliers_influence import reset_ramsey
# 警告メッセージを非表示
import warnings
warnings.filterwarnings("ignore")
説明#
<仮定5(均一分散; Homogeneity)が満たされない場合>
仮定5の均一分散の下では説明変数は誤差項の分散に影響を与えない。即ち,
この仮定に関連して次の点について留意する必要がある。
均一分散が満たされない場合でも,
仮定1〜4のもとでOLS推定量 \(\hat{\beta}_j\)の不遍性と一致性は成立する。
\(R^2\)の解釈は変わらない。
しかし,均一分散が満たされない場合,
OLS推定量の標準偏差の推定量である標準誤差\(\text{se}\left(\hat{\beta}_j\right)\)は無効となる。従って,\(t\)検定と\(F\)検定も無効になる。
大標本特性(漸近的特性)も成立しない。従って,大標本であっても\(t\)検定と\(F\)検定も無効になる。
仮説を検証するということを目的とすると,検定が無効というのは致命的な問題である。特に,不均一分散(Heteroskedasticity)の問題は,横断面データを使うと頻繁に出てくる問題である。ではどのように対応すればよいのか。
不均一分散頑健的推定(Heteroskedasticity-Robust Inference)
この手法を使うと,OLS推定量の標準誤差が調整され未知の不均一分散であっても,\(t\)検定,\(F\)検 定が有効になるというものである。
(理由)均一分散であっても不均一分散であっても,\(n\rightarrow\infty\)の場合,不均一分散頑健的推定の\(t\)(\(F\))値は\(t\)(\(F\))分布に従う。言い換えると,標本の大きさが十分に大きければ,\(t\)(\(F\))値の分布は\(t\)(\(F\))分布で近似できるということである。
更なる利点は,通常のOLS推定の後に標準誤差の調整が施され,計算はstatsmodelsを使うと簡単におこなうことが可能である。
(注意)大標本でのみ有効。
不均一分散頑健的推定では,OLS推定の共分散行列(covariance matrix)と呼ばれる箇所を調整し,OLS推定量の標準誤差を修正する。その調整方法が複数提案されていおり,statsmodelsでは以下の種類に対応している。
HC0: White (1980)の不均一分散頑健共分散行列推定HC1: MacKinnon and White (1985)の不均一分散頑健共分散行列推定v1HC2: MacKinnon and White (1985)の不均一分散頑健共分散行列推定v2HC3: MacKinnon and White (1985)の不均一分散頑健共分散行列推定v3
ここでHCはHeteroskedasticity-Consistent Covariance Matrix EstimatorsのHとC。
不均一分散頑健共分散行列推定を使い計算した\(t\)値や\(F\)値を頑健的\(t\)値,頑健的\(F\)値と呼ぶことにする。
Note
HC0などは不均一分散に対応する推定方法である。一方で,時系列分析では残差に不均一分散と自己相関の両方が存在する場合がある。この両方の問題に頑健的な推定を不均一分散・自己相関頑健推定(Heteroskedasticity-Autocorrelation Robust Inference)と呼ぶ。次の引数を使うことにより,不均一分散・自己相関頑健標準誤差を計算することができる。
cov_type='HAC', cov_kwds={'maxlags': n}, use_t=True
cov_type='HAC':不均一分散・自己相関頑健推定の指定cov_kwds={'maxlags': n}(必須):nは残差のラグを示し,nの値に基づきパラメータの推定値の標準誤差を調整する。n=10とすれば10までのラグを考慮し計算する。標本の大きさより小さな値を設定する必要がある。forループを使いnを変化させて、標準誤差がどう変化するかを確認するのも良いだろう。また、nを決める一つのルールとして次を紹介しよう。Newey and West (1987)が提案したルール:
Nを標本の大きさとすると、次の値の整数部分をnに使う。
use_t=True(必須ではない):t検定を使うことを指定する。
ちなみに,HCはHeteroskedasticity Consistentの略であり,HACはHeteroskedasticity-Autocorrelation Consistentの略である。
OLS推定量の不均一分散頑健標準偏差が簡単に計算できるのであれば,通常の標準偏差を使う必要はないのではないか,という疑問が生じる。この問を関して以下の点を考える必要がある。
通常の標準偏差を使う利点
均一分散の場合(仮定1〜6(CLR仮定)),標本の大きさの大小に関わらず,\(t\) (\(F\))値の分布は厳密に \(t\) (\(F\))分布に従う。
不均一分散頑健標準偏差
小標本の場合
頑健的 \(t\) (\(F\))値の分布は必ずしも \(t\) (\(F\))分布に従うわけではない。その場合,\(t\) (\(F\))検定は無効となる。
大標本の場合
\(t\) (\(F\))値の分布は \(t\) (\(F\))分布で近似され,\(t\) (\(F\))検定は有効である。
この結果は仮定1〜6(CLR仮定)のもとでも同じ。
従って,標本の大きさが「大標本」と判断できる場合(例えば,\(n\geq 1000\))以外は通常の標準偏差と不均一分散頑健標準偏差の両方を表示することを勧める。
頑健的\(t\)検定#
wooldridgeパッケージのデータセットgpa3を使い説明する。この例では大学のGPAと高校の成績や性別,人種などがどのような関係にあるかを探る。
gpa3 = wooldridge.data('gpa3').query('spring == 1') # 春学期だけを抽出
wooldridge.data('gpa3', description=True)
name of dataset: gpa3
no of variables: 23
no of observations: 732
+----------+------------------------------+
| variable | label |
+----------+------------------------------+
| term | fall = 1, spring = 2 |
| sat | SAT score |
| tothrs | total hours prior to term |
| cumgpa | cumulative GPA |
| season | =1 if in season |
| frstsem | =1 if student's 1st semester |
| crsgpa | weighted course GPA |
| verbmath | verbal SAT to math SAT ratio |
| trmgpa | term GPA |
| hssize | size h.s. grad. class |
| hsrank | rank in h.s. class |
| id | student identifier |
| spring | =1 if spring term |
| female | =1 if female |
| black | =1 if black |
| white | =1 if white |
| ctrmgpa | change in trmgpa |
| ctothrs | change in total hours |
| ccrsgpa | change in crsgpa |
| ccrspop | change in crspop |
| cseason | change in season |
| hsperc | percentile in h.s. |
| football | =1 if football player |
+----------+------------------------------+
See GPA2.RAW
gpa2に一部の変数の説明が続いている。
wooldridge.data('gpa2', description=True)
name of dataset: gpa2
no of variables: 12
no of observations: 4137
+----------+----------------------------------+
| variable | label |
+----------+----------------------------------+
| sat | combined SAT score |
| tothrs | total hours through fall semest |
| colgpa | GPA after fall semester |
| athlete | =1 if athlete |
| verbmath | verbal/math SAT score |
| hsize | size grad. class, 100s |
| hsrank | rank in grad. class |
| hsperc | high school percentile, from top |
| female | =1 if female |
| white | =1 if white |
| black | =1 if black |
| hsizesq | hsize^2 |
+----------+----------------------------------+
For confidentiality reasons, I cannot provide the source of these
data. I can say that they come from a midsize research university
that also supports men’s and women’s athletics at the Division I
level.
OLS推定#
被説明変数:
cumgpa:累積GPA
説明変数
sat:SATの成績hsperc:高校の成績の%点(上位から)tothrs:データ抽出時から学期までの時間?(gpa3の定義)female:女性ダミー変数(女性=1)black:人種ダミー変数(黒人=1)white:人種ダミー変数(白人=1)
form_ols = 'cumgpa ~ sat + hsperc + tothrs + female + black + white'
mod_ols = smf.ols(form_ols, data=gpa3)
res_ols = mod_ols.fit()
print(res_ols.summary().tables[1])
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 1.4701 0.230 6.397 0.000 1.018 1.922
sat 0.0011 0.000 6.389 0.000 0.001 0.001
hsperc -0.0086 0.001 -6.906 0.000 -0.011 -0.006
tothrs 0.0025 0.001 3.426 0.001 0.001 0.004
female 0.3034 0.059 5.141 0.000 0.187 0.420
black -0.1283 0.147 -0.870 0.385 -0.418 0.162
white -0.0587 0.141 -0.416 0.677 -0.336 0.219
==============================================================================
不均一分散頑健推定:方法1#
上のOLSの結果を使い頑健\(t\)値を計算するために,res_olsのメソッド.get_robustcov_results()を使う。
オプション
cov_typeは頑健性の計算法の指定(デフォルトはCH1)。オプション
use_tは\(t\)検定を指定(デフォルトはNoneで「自動」に決められる)
res_robust = res_ols.get_robustcov_results(cov_type='HC3', use_t=True)
print(res_robust.summary().tables[1])
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 1.4701 0.229 6.409 0.000 1.019 1.921
sat 0.0011 0.000 5.840 0.000 0.001 0.002
hsperc -0.0086 0.001 -5.934 0.000 -0.011 -0.006
tothrs 0.0025 0.001 3.342 0.001 0.001 0.004
female 0.3034 0.060 5.054 0.000 0.185 0.422
black -0.1283 0.128 -1.001 0.318 -0.380 0.124
white -0.0587 0.120 -0.488 0.626 -0.296 0.178
==============================================================================
OLS推定量
coefの値は同じであり,必ずそうなる。不均一分散頑健推定は,表の中で標準誤差,\(t\)値,\(p\)値,信頼区間に影響を与える。標準誤差
std errを比べると,帰無仮説\(\hat{\beta}_j=0\)の棄却判断を覆すほど大きく変わる変数はない。これは不均一分散がそれほど大きな問題ではないことを示唆している。この点を確かめるために,res_olsの誤差項を図示してみる。
誤差項を図示する方法として2つを紹介する。一つ目は,res_olsの属性.residを使う。res_ols.residはPandasのSeries(シリーズ)なので,そのメソッドplot()を使い図示する。styleはマーカーを指定するオプション。
res_ols.resid.plot(style='o')
pass
2つ目の方法はplt.plot()を使う。オップション'o'はマーカの指定である。
plt.plot(res_ols.resid, 'o')
pass
3つ目はscatter()を使う。.indexはres_ols.resdの属性でインデックスを示す。
plt.scatter(res_ols.resid.index, res_ols.resid)
pass
不均一分散頑健推定:方法2#
OLS推定をする際,fit()の関数に.get_robustcov_results()で使った同じオプションを追加すると頑健\(t\)値などを直接出力できる。
res_HC3 = smf.ols(form_ols, data=gpa3).fit(cov_type='HC3', use_t=True)
print(res_HC3.summary().tables[1])
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 1.4701 0.229 6.409 0.000 1.019 1.921
sat 0.0011 0.000 5.840 0.000 0.001 0.002
hsperc -0.0086 0.001 -5.934 0.000 -0.011 -0.006
tothrs 0.0025 0.001 3.342 0.001 0.001 0.004
female 0.3034 0.060 5.054 0.000 0.185 0.422
black -0.1283 0.128 -1.001 0.318 -0.380 0.124
white -0.0587 0.120 -0.488 0.626 -0.296 0.178
==============================================================================
頑健的\(F\)検定#
同じデータgpa3を使い,黒人ダミーと白人ダミーの係数は両方とも0という仮説を検定する。
hypotheses = 'black = white = 0'
まず通常の\(F\)検定を考える。
f_test_ols = res_ols.f_test(hypotheses)
f_test_ols.summary()
'<F test: F=0.6796041956073341, p=0.5074683622584049, df_denom=359, df_num=2>'
返り値(左から)
F statistic:\(F\)統計量F p-value:\(F\)の\(p\)値df_denom:分母の自由度df_num:分子の自由度
次に頑健\(F\)検定の方法を説明する。上の不均一分散頑健推定の方法2で使ったf_test_HC3を使う。
f_test_HC3 = res_HC3.f_test(hypotheses)
f_test_HC3.summary()
'<F test: F=0.6724692957656627, p=0.5110883633440992, df_denom=359, df_num=2>'
\(t\)検定の場合と同じように,大きく変わる結果につながってはない。
均一分散の検定#
均一分散の場合 \(t\)(\(F\))値は厳密に\(t\)(\(F\))分散に従う。それが故に,均一分散が好まれる理由である。ここでは均一分散の検定について考える。帰無仮説と対立仮説は以下となる。
\(\text{H}_0\):誤差項は均一分散
\(\text{H}_A\):帰無仮説は成立しない
2つの検定方法を考える。
ブルーシュ・ペーガン(Breusch-Pagan)検定#
データhprice1を使って,住宅価格の決定要因を検討する。ここで考える均一分散の検定にBreusch-Pagan検定と呼ばれるもので,statsmodelsのサブパッケージstatsの関数het_breuschpaganを使う。
hprice1 = wooldridge.data('hprice1')
wooldridge.data('hprice1', description=True)
name of dataset: hprice1
no of variables: 10
no of observations: 88
+----------+------------------------------+
| variable | label |
+----------+------------------------------+
| price | house price, $1000s |
| assess | assessed value, $1000s |
| bdrms | number of bdrms |
| lotsize | size of lot in square feet |
| sqrft | size of house in square feet |
| colonial | =1 if home is colonial style |
| lprice | log(price) |
| lassess | log(assess |
| llotsize | log(lotsize) |
| lsqrft | log(sqrft) |
+----------+------------------------------+
Collected from the real estate pages of the Boston Globe during 1990.
These are homes that sold in the Boston, MA area.
以下で使う変数について。
被説明変数
price:住宅価格(単位:1000ドル)
説明変数
lotsize:土地面積(単位:平方フィート)sqrft:家の面積(単位:平方フィート)bdrms:寝室の数
対数変換前#
まず変数の変換をしない場合を考える。
form_h = 'price ~ lotsize + sqrft + bdrms'
res_h = smf.ols(form_h, data=hprice1).fit()
print(res_h.summary().tables[1])
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept -21.7703 29.475 -0.739 0.462 -80.385 36.844
lotsize 0.0021 0.001 3.220 0.002 0.001 0.003
sqrft 0.1228 0.013 9.275 0.000 0.096 0.149
bdrms 13.8525 9.010 1.537 0.128 -4.065 31.770
==============================================================================
この結果に対してBreusch-Pagan検定をおこなう。het_breuschpagan()の引数について:
第1引き数:OLSの結果
res_hの属性.residで誤差項の値第2引き数:OLSの結果
res_hの属性.modelの属性exogを使い定数項を含む説明変数の値
het_breuschpagan(res_h.resid, res_h.model.exog)
(14.092385504350194,
0.002782059555689147,
5.338919363241398,
0.002047744420936124)
返り値(上から)
LM statistic:\(LM\)統計量LM p-value:\(LM\)の\(p\)値F statistics:\(F\)統計量F p-value:\(F\)の\(p\)値
\(LM\)検定とはLagrange Multiplier検定のことで,大標本の場合に仮定1〜4(GM仮説)のもとで成立する。一般にBreusch-Pagan検定は\(LM\)統計量を使ったものを指すが,\(F\)統計量としても計算できる。
5%の有意水準で帰無仮説(\(\text{H}_0\):誤差項は均一分散)を棄却でき,不均一分散の可能性が高い。対処法として変数の変換が挙げられる。
対数変換#
bdrms以外を対数変換する。
form_h_log = 'np.log(price) ~ np.log(lotsize) + np.log(sqrft) + bdrms'
res_h_log = smf.ols(form_h_log, data=hprice1).fit()
print(res_h_log.summary().tables[1])
===================================================================================
coef std err t P>|t| [0.025 0.975]
-----------------------------------------------------------------------------------
Intercept -1.2970 0.651 -1.992 0.050 -2.592 -0.002
np.log(lotsize) 0.1680 0.038 4.388 0.000 0.092 0.244
np.log(sqrft) 0.7002 0.093 7.540 0.000 0.516 0.885
bdrms 0.0370 0.028 1.342 0.183 -0.018 0.092
===================================================================================
het_breuschpagan(res_h_log.resid, res_h_log.model.exog)
(4.223245741805286,
0.23834482631492918,
1.4114999061208104,
0.24514566130489174)
5%の有意水準でお帰無仮説を棄却できない。即ち,対立仮説(\(\text{H}_A\):帰無仮説は成立しない)を採択し,均一分散の可能性が高い。
ホワイト(White)検定#
この検定はOLS推定量の標準誤差と検定統計量を無効にする不均一分散を主な対象としており,Breusch-Pagan検定よりもより一般的な式に基づいて検定をおこなう。statsmodelsのサブパッケージstatsの関数het_whiteを使う。
hpriceのデータを使った上の例を使う。
het_white()の引数:
第1引き数:OLSの結果
res_hの属性.residで誤差項の値第2引き数:OLSの結果
res_hの属性.modelの属性exogを使い定数項を含む説明変数の値
対数変換前#
het_white(res_h.resid, res_h.model.exog)
(33.731657711098364,
9.9529397737343e-05,
5.386953445894592,
1.0129388323900798e-05)
返り値(上から)
LM statistic:\(LM\)統計量LM p-value:\(LM\)の\(p\)値F statistics:\(F\)統計量F p-value:\(F\)の\(p\)値
一般にWhite検定は\(LM\)統計量を使ったものを指すが,\(F\)統計量としても計算できる。
5%の有意水準で帰無仮説(\(\text{H}_0\):誤差項は均一分散)を棄却でき,不均一分散の可能性が高い。対処法として変数の変換が挙げられる。
対数変換後#
het_white(res_h_log.resid, res_h_log.model.exog)
(9.549452426207322,
0.38817399191075586,
1.0549565756603805,
0.4053123705653102)
5%の有意水準で帰無仮説を棄却できない。即ち,対立仮説(\(\text{H}_A\):帰無仮説は成立しない)を採択し,均一分散の可能性が高い。
残差:図示と線形性#
図示#
仮定4〜6は残差に関するものであり,残差をプロットし不均一分散や非線形性を確認することは回帰分析の重要なステップである。
残差を図示する方法としてlmdiag以外に以下を紹介する。
matplotlibを直接使うseabornというパッケージの中にある関数residplotを使う
上で計算したres_hとres_h_logを利用し
横軸:被説明変数の予測値(メソッド
.fittedvalues)縦軸:残差(メソッド
.resid)
となる図を作成する。
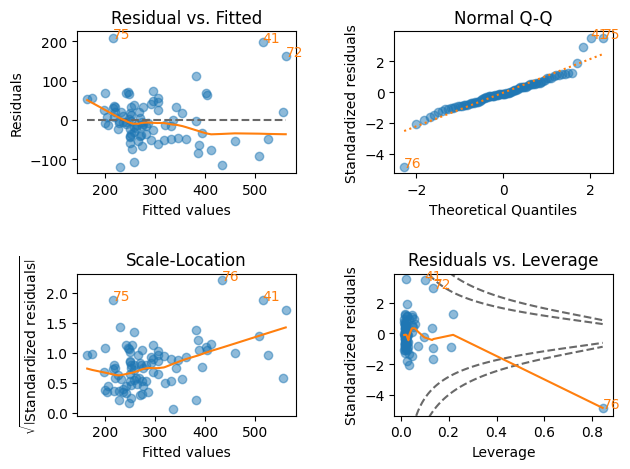
lmdiag#
対数変換前
plt.figure(figsize=(8,7))
lmdiag.plot(res_h)
pass
<Figure size 800x700 with 0 Axes>
対数変換後
plt.figure(figsize=(8,7))
lmdiag.plot(res_h_log)
pass
<Figure size 800x700 with 0 Axes>
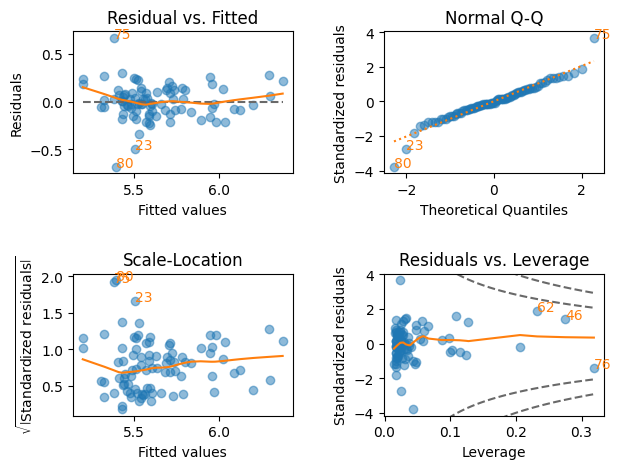
対数変換により残差の変化がより均一的になり,Residuals vs. LeverageのCook’s Distanceを見ても外れ値がなくなっている。
Matplotlibのplot()#
対数変換前
plt.scatter(res_h.fittedvalues, res_h.resid)
pass
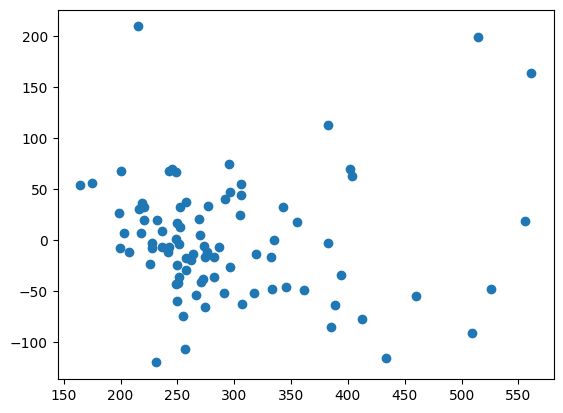
対数変換後
plt.scatter(res_h_log.fittedvalues, res_h_log.resid)
pass
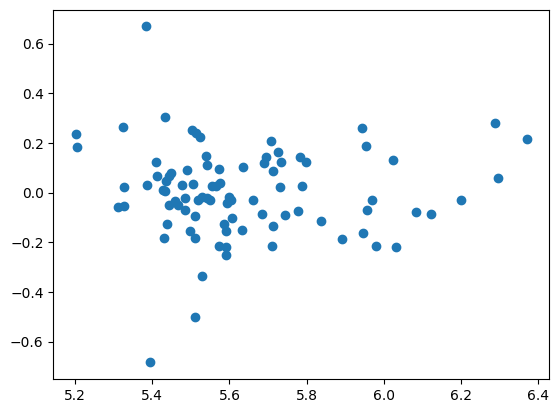
対数変換により残差の変化がより均一的になったのが確認できる。
seabornのresidplot()#
seabornはmatplotlibを利用し様々な図を描ける。seabornについてはこのサイトを参照。
通常import seaborn as snsでインポートすることが多いようであるが,ここではresidplotのみをインポートしている。
residplot()は散布図を作成する関数である。
x=:横軸の変数を指定被説明変数を設定することを勧める。
y=:縦軸の変数を指定残差
オプション
lowerss=True(デフォルトはFalse)にすると,散布図にベスト・フィットする曲線を表示する。
対数変換前
residplot(x=res_h.fittedvalues, y=res_h.resid, lowess=True)
pass
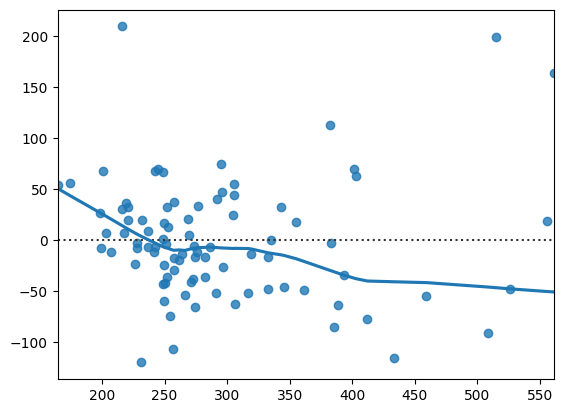
対数変換後
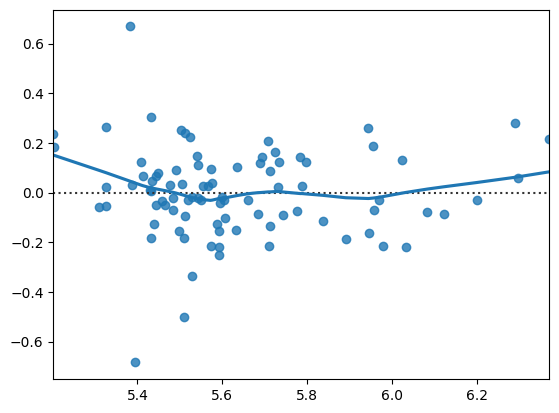
residplot(x=res_h_log.fittedvalues, y=res_h_log.resid, lowess=True)
pass
線形性#
仮定1で回帰式は線形となっているが,その仮定が正しければ,上の残差の散布図は概ね平行にそして0を中心に上下等間隔に散らばることになる。そのパターンに比較的に近いのは対数変換後の図である。不均一分散の場合は,そのパターンが大きく崩れている場合であり,その原因のその1つに回帰式の特定化の間違いがある。例えば,説明変数の2乗が含まれるべきなのに欠落している場合が挙げられる。極端な場合,残差の散布図は\(U\)字または逆\(U\)字のような形になりえる。
一方,線形性の検定もある。以下ではその1つである RESET (Regression Specification Error Test) 検定を考える。
この検定の考え方はそれほど難しくはない。次の回帰式を推定するとしよう。
この線形式が正しければ,\(x_1^2\)や\(x_2^3\)等を追加しても統計的に有意ではないはずである。さらに,この線形回帰式の予測値\(\hat{y}\)は\(x_1\)や\(x_2\)の線形になっているため、\(\hat{y}^2\)や\(\hat{y}^3\)は\(x_1\)や\(x_2\)の非線形となっている。従って,次式を推計し,もし非線形の効果がなければ\(\delta_1\)も\(\delta_2\)も有意ではないはずである。
この考えに基づいて以下の仮説を検定する。
\(\text{H}_0:\;\delta_1=\delta_2=0\)(線形回帰式が正しい)
\(\text{H}_A\): \(\text{H}_0\)は成立しない
<コメント>
通常は\(y\)の3乗まで含めれば十分であろう。
大標本のもとで\(F\)検定統計値は\(F\)分布に従う。
statsmodelsのサブパッケージ.stats.outliers_influenceのRESET検定用の関数reset_ramseyを使う。(ramseyはこの検定を考案した学者名前)
reset_ramsey()の使い方:
引き数:OLS推定の結果
オプションの
degree(デフォルトは5)は\(y\)の何乗までを含めるかを指定する。
対数変換前
reset_ramsey(res_h,degree=3).summary()
'<F test: F=4.668205534948428, p=0.012021711442886855, df_denom=82, df_num=2>'
返り値
F: \(F\)統計量p: \(p\)値df_denom: 分母の自由度df_num: 分子の自由度(2乗以上の制約数)
対数変換後
reset_ramsey(res_h_log,degree=3)
<class 'statsmodels.stats.contrast.ContrastResults'>
<F test: F=2.5650407879824693, p=0.08307588974934489, df_denom=82, df_num=2>
5%の有意水準のもとで,res_hの帰無仮説を棄却できるが,res_h_logでは棄却できない。後者の推計式がより適しているようである。