離散選択モデル#
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import py4macro
import wooldridge
from py4etrics.hetero_test import *
from scipy.stats import logistic, norm, chi2
from statsmodels.formula.api import ols, logit, probit
# 警告メッセージを非表示
import warnings
warnings.filterwarnings("ignore")
説明#
次の2つのモデルを考える。
Logitモデル
Probitモデル
例として,労働市場参加の決定要因を考えよう。就業する場合は\(y=1\),しない場合は\(y=0\)となる2値反応モデルと考えることができる。
<考え方>
潜在変数(効用とも解釈可能) \(y^{*}\) が \(y^{*}>0\) の場合は労働市場に参加し,\(y^{*}\leq0\) の場合は参加しないとする。
\(y^{*}\)は要因\(x\)と誤差項に依存する。
\[\begin{split} y= \begin{cases} 1\quad\text{ if}&y^{*}=\beta_0+\beta_1x+e > 0\\ 0\quad\text{ if}&y^{*}=\beta_0+\beta_1x+e \leq 0\\ \end{cases} \qquad (式0) \end{split}\]\(\beta_0\):定数項
\(\beta_1\):要因\(x\)の影響を捉える係数
\(e\):誤差項
\(x\)(例えば,教育水準)が同じであっても,\(e\)(例えば,嗜好)によって労働市場参加の決定が異なる。
\(x\)を所与として労働市場に参加する確率:\(P(y=1|x)\)を考えよう。
\[ P(y=1|x)=P(y^{*}>0|x)=P(e>-(\beta_0+\beta_1x)|x)=1-G(-(\beta_0+\beta_1x))\]ここでG(.)はeの累積分布関数である。対称分布関数を仮定すると
\[ 1-G(-z)=G(z)\qquad\; z=\beta_0+\beta_1x\]となる。また\(G(.)\)にどの分布を仮定するかによって,LogitモデルとProbitモデルに分けることができる。
Logitモデル:\(e\)はLogistic分布に従うと仮定
\[G(z)=L(z)=\dfrac{\exp(z)}{1+\exp(z)}:\quad\text{(Logistic累積確率分布)}\]Probitモデル:\(e\)は標準正規分布に従うと仮定
\[G(z)=\Phi(z)=\text{標準正規分布の累積確率分布}\]
LogitモデルとProbitモデルは次式で表される。
\[\begin{split} P(y=1|x)=G(\beta_0+\beta_1x)= \begin{cases} L(\beta_0+\beta_1x)&\;\text{Logitモデル}\\ \Phi(\beta_0+\beta_1x)&\;\text{Probitモデル} \end{cases} \qquad\text{(式1)} \end{split}\]
下の図はロジスティクス分布と標準正規分布の累積密度関数を表している。
x = np.linspace(-4,4,100)
y_logistic = logistic.cdf(x)
y_norm = norm.cdf(x)
plt.plot(x, y_logistic,label='Logistic')
plt.plot(x, y_norm, label='Normal')
plt.hlines(y=0.5,xmin=-4,xmax=4,linestyles='--')
plt.xlabel('z')
plt.title(r'Cumulative Distribution Functions: $G(z)$')
plt.legend()
plt.grid()
pass
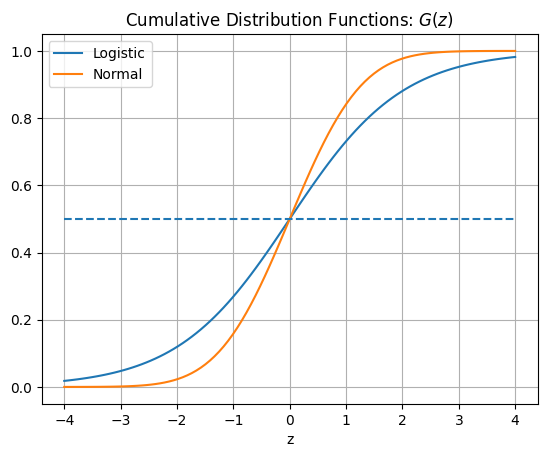
(コメント)
(式1)に使うデータ
左辺の被説明変数:\(y=\{0,1\}\)
右辺の説明変数:\(x\)は通常の変数
(式1)を最尤法(Maximum Likelihood Estimate; MLE)を使って非線形推定
推定には
statsmodelsを使う。(式1)の推計に基づく予測値 = \(x\)を所与とする労働市場に参加する確率
OLS推定では検定に\(t\)・\(F\)検定を使ったが,その代わりに最尤法のもとでの検定には3つある
Wald検定
尤度比検定(Likelihood Ratio Test)
LM(Lagrange Multiplier)検定(Score検定とも呼ばれる)
(大標本のもとで同じとなる; 使いやすいものを選択)
(注意1)
「理想的な」仮定のもとで,最尤推定量は
一致性を満たす
漸近的に(大標本)正規分布に従う
漸近的に(大標本)効率的である
最尤推定量が一致性を満たさない要因に以下を含む(Green, 5th ed, p.679)
誤差項の不均一分散
内生的説明変数
欠落変数(右辺にある説明変数と相関しなくてもバイアスが発生する)
<<不均一分散が疑われる場合の問題>>
OLS推定(復習であり,ここでは使わない)
推定量は不偏性・一致性を満たす
標準誤差は一致性を失う
不均一分散頑健標準誤差を使うことにより,有効な検定を行うことが可能(即ち,推定量は一致性を満たしているので,標準誤差を修正することにより有効な検定となる)
ML推定
推定量は一致性を満たさない
標準誤差も一致性を満たさない
不均一分散頑健標準誤差を使うことが推奨されることがあるが(研究論文でもそうする研究者も多い)。しかし,係数の推定量は一致性を満たさないままなので,標準誤差だけを修正してもどこまで意味があるのか疑問である。即ち,この場合の不均一分散頑健標準誤差の有用性に疑問が残る(参照)。このことは次章の制限従属変数モデルに当てはまるので注意すること。
不均一分散に関しての対処方法
均一分散の下での標準誤差と不均一分散頑健標準誤差に大きな差がなければ,不均一分散の問題は「大きくない」と考える。ただし目安。
不均一分散の検定をおこなう。
推定#
データ#
以下では,mrozのデータを使って女性の労働市場参加について考える。
mroz = wooldridge.data('mroz')
wooldridge.data('mroz', description=True)
name of dataset: mroz
no of variables: 22
no of observations: 753
+----------+---------------------------------+
| variable | label |
+----------+---------------------------------+
| inlf | =1 if in lab frce, 1975 |
| hours | hours worked, 1975 |
| kidslt6 | # kids < 6 years |
| kidsge6 | # kids 6-18 |
| age | woman's age in yrs |
| educ | years of schooling |
| wage | est. wage from earn, hrs |
| repwage | rep. wage at interview in 1976 |
| hushrs | hours worked by husband, 1975 |
| husage | husband's age |
| huseduc | husband's years of schooling |
| huswage | husband's hourly wage, 1975 |
| faminc | family income, 1975 |
| mtr | fed. marg. tax rte facing woman |
| motheduc | mother's years of schooling |
| fatheduc | father's years of schooling |
| unem | unem. rate in county of resid. |
| city | =1 if live in SMSA |
| exper | actual labor mkt exper |
| nwifeinc | (faminc - wage*hours)/1000 |
| lwage | log(wage) |
| expersq | exper^2 |
+----------+---------------------------------+
T.A. Mroz (1987), “The Sensitivity of an Empirical Model of Married
Women’s Hours of Work to Economic and Statistical Assumptions,”
Econometrica 55, 765-799. Professor Ernst R. Berndt, of MIT, kindly
provided the data, which he obtained from Professor Mroz.
被説明変数
inlf:1975年に労働市場に参加した場合1,しない場合は0
説明変数
nwifeinc:(faminc-wage*hours)/1000faminc:1975年の世帯所得wage:賃金hours:就業時間
educ:教育年数exper:労働市場参加期間expersq:experの2乗age:女性の年齢kidslt6:6歳未満の子供の数kidsge6:6〜18さいの子供の数
Logitモデル#
回帰式の設定
formula = 'inlf ~ nwifeinc + educ + exper + expersq + age + kidslt6 + kidsge6'
推定の計算にはstatsmodelsのlogit関数を使う。使い方はstatsmodelsのolsと同じである。
res_logit = logit(formula, data=mroz).fit()
Optimization terminated successfully.
Current function value: 0.533553
Iterations 6
結果の表示
print(res_logit.summary())
Logit Regression Results
==============================================================================
Dep. Variable: inlf No. Observations: 753
Model: Logit Df Residuals: 745
Method: MLE Df Model: 7
Date: Sat, 20 Sep 2025 Pseudo R-squ.: 0.2197
Time: 00:35:13 Log-Likelihood: -401.77
converged: True LL-Null: -514.87
Covariance Type: nonrobust LLR p-value: 3.159e-45
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 0.4255 0.860 0.494 0.621 -1.261 2.112
nwifeinc -0.0213 0.008 -2.535 0.011 -0.038 -0.005
educ 0.2212 0.043 5.091 0.000 0.136 0.306
exper 0.2059 0.032 6.422 0.000 0.143 0.269
expersq -0.0032 0.001 -3.104 0.002 -0.005 -0.001
age -0.0880 0.015 -6.040 0.000 -0.117 -0.059
kidslt6 -1.4434 0.204 -7.090 0.000 -1.842 -1.044
kidsge6 0.0601 0.075 0.804 0.422 -0.086 0.207
==============================================================================
dir()やpy4macro.see()を使うと,推定結果の属性やメソッドを確認できる。
py4macro.see(res_logit)
.aic .bic .bse .conf_int()
.converged .cov_kwds .cov_params() .cov_type
.df_model .df_resid .f_test() .fittedvalues
.get_distribution() .get_influence() .get_margeff() .get_prediction()
.im_ratio .info_criteria() .initialize() .k_constant
.llf .llnull .llr .llr_pvalue
.load() .method .mle_retvals .mle_settings
.model .nobs .normalized_cov_params .params
.pred_table() .predict() .prsquared .pvalues
.remove_data() .resid_dev .resid_generalized .resid_pearson
.resid_response .save() .scale .score_test()
.set_null_options() .summary() .summary2() .t_test()
.t_test_pairwise() .tvalues .use_t .wald_test()
.wald_test_terms()
例えば,bseは係数の標準誤差の属性である。
不均一分散について考察する。誤差項の分散が均一か不均一かを考える上で,2つの方法を説明する。
不均一分散頑健標準誤差を使う場合と使わない場合の標準誤差を比べる。
違いが小さければ,均一分散の可能性が高い。
しかし,これは1つの目安である。
検定を用いる
考え方:不均一分散の仮定の下で最尤推定し,均一分散と比較する。
方法1を考えよう。
# 上で推定した係数の標準誤差。
l0=res_logit.bse
# 不均一分散頑健標準誤差
l1=logit(formula, data=mroz).fit(cov_type='HC1',disp=False).bse
# `HC1`を使うことによる標準誤差の変化率(%)
100*(l1-l0)/l0
Intercept -0.140629
nwifeinc 7.726361
educ 2.259971
exper 0.664423
expersq -0.427766
age -0.983628
kidslt6 -0.274232
kidsge6 6.738482
dtype: float64
大きく違っているようにもみえない。
次に方法2である検定をおこなう。まずpy4etricsパッケージにあるhetero_testモジュールを読み込み,その中にhet_test_logit()という関数をつかう。
Note
MacではTerminal、WindowsではGit Bashを使い、次のコマンドでpy4etricsモジュールをインストールできる。
pip install git+https://github.com/spring-haru/py4etrics.git
引数に推定結果のインスタンスを指定することにより,不均一分散のWald検定をおこなうことができる。
het_test_logit(res_logit)
H0: homoscedasticity
HA: heteroscedasticity
Wald test: 9.547
p-value: 0.216
df freedom: 7
10%の有意水準でも均一分散の帰無仮説を棄却できない。
Probitモデル#
推定の計算にはstatsmodelsのprobit関数を使う。使い方はlogitと同じである。上と同じデータと同じformulaを使う。
res_probit = probit(formula, data=mroz).fit()
Optimization terminated successfully.
Current function value: 0.532938
Iterations 5
print(res_probit.summary())
Probit Regression Results
==============================================================================
Dep. Variable: inlf No. Observations: 753
Model: Probit Df Residuals: 745
Method: MLE Df Model: 7
Date: Sat, 20 Sep 2025 Pseudo R-squ.: 0.2206
Time: 00:35:13 Log-Likelihood: -401.30
converged: True LL-Null: -514.87
Covariance Type: nonrobust LLR p-value: 2.009e-45
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 0.2701 0.509 0.531 0.595 -0.727 1.267
nwifeinc -0.0120 0.005 -2.484 0.013 -0.022 -0.003
educ 0.1309 0.025 5.183 0.000 0.081 0.180
exper 0.1233 0.019 6.590 0.000 0.087 0.160
expersq -0.0019 0.001 -3.145 0.002 -0.003 -0.001
age -0.0529 0.008 -6.235 0.000 -0.069 -0.036
kidslt6 -0.8683 0.119 -7.326 0.000 -1.101 -0.636
kidsge6 0.0360 0.043 0.828 0.408 -0.049 0.121
==============================================================================
dir()やpy4macro.see()を使うと,推定結果の属性やメソッドを確認できる。
py4macro.see(res_probit)
.aic .bic .bse .conf_int()
.converged .cov_kwds .cov_params() .cov_type
.df_model .df_resid .f_test() .fittedvalues
.get_distribution() .get_influence() .get_margeff() .get_prediction()
.im_ratio .info_criteria() .initialize() .k_constant
.llf .llnull .llr .llr_pvalue
.load() .method .mle_retvals .mle_settings
.model .nobs .normalized_cov_params .params
.pred_table() .predict() .prsquared .pvalues
.remove_data() .resid_dev .resid_generalized .resid_pearson
.resid_response .save() .scale .score_test()
.set_null_options() .summary() .summary2() .t_test()
.t_test_pairwise() .tvalues .use_t .wald_test()
.wald_test_terms()
不均一分散について考察する。
# 上で推定した係数の標準誤差。
p0=res_probit.bse
# 不均一分散頑健標準誤差
p1=probit(formula, data=mroz).fit(cov_type='HC1',disp=False).bse
# `HC1`を使うことによる標準誤差の変化率(%)
100*(p1-p0)/p0
Intercept -0.738030
nwifeinc 9.653354
educ 2.169440
exper 0.666688
expersq 0.055315
age -1.528876
kidslt6 -2.021420
kidsge6 4.114557
dtype: float64
大きく違っているようにはみえない。
次に検定をおこなう。py4etricsパッケージのhetero_testモジュールにあるhet_test_probit()という関数を使う。使い方はhet_test_probit()とおなじである。
het_test_probit(res_probit)
H0: homoscedasticity
HA: heteroscedasticity
Wald test: 8.665
p-value: 0.278
df freedom: 7
10%の有意水準でも均一分散の帰無仮説を棄却できない。
係数の推定値の解釈#
まず,logitとprobitの結果を比べてわかるのは,係数の推定値は非常に似ているという点である。では,係数をどのように解釈できるのか考える。
<通常のOLSの場合>
推定式が
の場合,\(\hat{\beta}_1\)の解釈は簡単である。\(\dfrac{\partial\hat{y}}{\partial x}=\hat{\beta}_1\)となるので,(他の変数を一定にしたまま)\(x\)を一単位変化させた場合の\(\hat{y}\)に対する限界効果である。その限界効果は\(x\)に依存せず一定である。
<Logit・Probitモデルの場合>
\(G(.)\)の関数があるため,少し違ってくる。(式1)を微分すると次の結果を得る。
重要な点は,\(g\left(\hat{\beta}_0+\hat{\beta}_1 x\right)\)は\(x\)に依存しているため,\(x\)が一単位変化した場合の限界効果は\(x\)の値に依存しているということである。限界効果を評価したい場合,\(x\)に何かの値を代入することにより評価する。ではどの値を使えば良いのか。2つの方法考える。
Partial Effects at Average(平均での限界効果):平均である\(\bar{x}\)で評価する。
\[ \text{PEA}= \hat{\beta}_1\cdot g\left(\hat{\beta}_0+\hat{\beta}_1\bar{x}\right) \]Average Partial Effects(平均限界効果):全ての\(x\)値で評価した限界効果の平均
\[ \text{APE}=\dfrac{1}{n}\sum_{i=1}^n \hat{\beta}_1\cdot g\left(\hat{\beta}_0+\hat{\beta}_1\hat{x}\right) \]
(解釈)
\(x\)が1単位増加すると労働市場参加の確率(\(P(y=1|x)=G(\beta_0+\beta_1x)\))はどれだけ変化するかを示す。
statsmodelsでは,推定結果(上の例では,res_logitとres_probit)のメソッドget_margeff()を使うことにより自動的に計算してくれる。デフォルトではAPEを返す。PEAには次の引数を使う。
PEA:
at='mean'APE:
at='overall'(デフォルト)
また,get_margeff()は計算するだけなので,メソッドsummary()を使って結果を表示する。
print(res_logit.get_margeff().summary())
print(res_logit.get_margeff(at='mean').summary())
Logit Marginal Effects
=====================================
Dep. Variable: inlf
Method: dydx
At: overall
==============================================================================
dy/dx std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
nwifeinc -0.0038 0.001 -2.571 0.010 -0.007 -0.001
educ 0.0395 0.007 5.414 0.000 0.025 0.054
exper 0.0368 0.005 7.139 0.000 0.027 0.047
expersq -0.0006 0.000 -3.176 0.001 -0.001 -0.000
age -0.0157 0.002 -6.603 0.000 -0.020 -0.011
kidslt6 -0.2578 0.032 -8.070 0.000 -0.320 -0.195
kidsge6 0.0107 0.013 0.805 0.421 -0.015 0.037
==============================================================================
Logit Marginal Effects
=====================================
Dep. Variable: inlf
Method: dydx
At: mean
==============================================================================
dy/dx std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
nwifeinc -0.0052 0.002 -2.534 0.011 -0.009 -0.001
educ 0.0538 0.011 5.092 0.000 0.033 0.074
exper 0.0501 0.008 6.397 0.000 0.035 0.065
expersq -0.0008 0.000 -3.096 0.002 -0.001 -0.000
age -0.0214 0.004 -6.046 0.000 -0.028 -0.014
kidslt6 -0.3509 0.050 -7.070 0.000 -0.448 -0.254
kidsge6 0.0146 0.018 0.804 0.422 -0.021 0.050
==============================================================================
print(res_probit.get_margeff().summary())
print(res_probit.get_margeff(at='mean').summary())
Probit Marginal Effects
=====================================
Dep. Variable: inlf
Method: dydx
At: overall
==============================================================================
dy/dx std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
nwifeinc -0.0036 0.001 -2.509 0.012 -0.006 -0.001
educ 0.0394 0.007 5.452 0.000 0.025 0.054
exper 0.0371 0.005 7.200 0.000 0.027 0.047
expersq -0.0006 0.000 -3.205 0.001 -0.001 -0.000
age -0.0159 0.002 -6.739 0.000 -0.021 -0.011
kidslt6 -0.2612 0.032 -8.197 0.000 -0.324 -0.199
kidsge6 0.0108 0.013 0.829 0.407 -0.015 0.036
==============================================================================
Probit Marginal Effects
=====================================
Dep. Variable: inlf
Method: dydx
At: mean
==============================================================================
dy/dx std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
nwifeinc -0.0047 0.002 -2.484 0.013 -0.008 -0.001
educ 0.0511 0.010 5.186 0.000 0.032 0.070
exper 0.0482 0.007 6.575 0.000 0.034 0.063
expersq -0.0007 0.000 -3.141 0.002 -0.001 -0.000
age -0.0206 0.003 -6.241 0.000 -0.027 -0.014
kidslt6 -0.3392 0.046 -7.316 0.000 -0.430 -0.248
kidsge6 0.0141 0.017 0.828 0.408 -0.019 0.047
==============================================================================
APEとPEAの値だけを取り題したい場合は,属性margeffを使うと良いだろう。
res_probit.get_margeff(at='mean').margeff
array([-0.00469623, 0.05112871, 0.04817705, -0.00073705, -0.02064317,
-0.33915138, 0.0140628 ])
推定結果の表(上段右)#
推定結果の表を説明するためにlogitの結果を再度表示する。(probitも同じ項目が表示されている)
print(res_logit.summary().tables[0])
Logit Regression Results
==============================================================================
Dep. Variable: inlf No. Observations: 753
Model: Logit Df Residuals: 745
Method: MLE Df Model: 7
Date: Sat, 20 Sep 2025 Pseudo R-squ.: 0.2197
Time: 00:35:13 Log-Likelihood: -401.77
converged: True LL-Null: -514.87
Covariance Type: nonrobust LLR p-value: 3.159e-45
==============================================================================
No. Observations:観測値の数(データの大きさ)属性
nobs
DF Residuals:定数以外の係数の数属性
df_resid
DF Model:定数以外の係数の数属性
df_model
Pseudo R-squ(疑似決定係数):MLEはOLSではないため\(R^2\)はない。その代わりになる指標がPseudo \(R^2\)(疑似決定係数)といわれるものであり,その1つが表にあるMcFaddenが考案した Pseudo \(R^2\)。
属性
prsquared
Log-Likelihood(残差の対数尤度)大きいほど当てはまり良い
属性
llf
LL-Null(定数以外の係数を0に制限した場合の残差の対数尤度)属性
llnull
LLR p-value:定数項(Intercept)以外の係数が全て0であるという帰無仮説のもとでのp値。ここでは非常に小さな数字であり,帰無仮説を棄却できる。
属性
llr_pvalue
尤度比検定#
尤度比検定(Likelihood Ratio Test)について説明する。検定量は,次式に従って制限を課す場合と課さない場合の残差の対数尤度を使って計算する。
\(\cal{L}_{ur}\):制限がない場合の対数尤度
\(\cal{L}_{r}\):制限がある場合の対数尤度
\(LR\)は漸近的にカイ二乗分布に従う。
例1#
例として,Probit推定を考える。
\(\text{H}_0\):定数項以外の係数は全て0
\(\text{H}_A\):\(\text{H}_0\)は成立しない
ll_ur = res_probit.llf # 制限を課さない場合の対数尤度
ll_r = res_probit.llnull # 制限を課す場合の対数尤度
LR = 2*(ll_ur-ll_r) # LR統計量
dof = res_probit.df_model # 自由度=制限を課すパラメータの数
1- chi2.cdf(LR, dof)
0.0
1%水準で帰無仮説は棄却できる。
この結果は推定結果の表にあるLLR p-valueと同じであり,res_probitの属性.llr_pvalueを使って直接表示することも可能である。
res_probit.llr_pvalue
2.0086732957629427e-45
例2#
次に,Probit推定を考える。
\(\text{H}_0\):exper,expersq,ageの係数は0
\(\text{H}_A\):\(\text{H}_0\)は成立しない
帰無仮説の下での推定をおこなう。
formula_0 = 'inlf ~ nwifeinc + educ + kidslt6 + kidsge6'
res_probit_0 = probit(formula_0, data=mroz).fit(cov_type='HC1')
Optimization terminated successfully.
Current function value: 0.617290
Iterations 5
ll_ur = res_probit.llf # 制限を課さない場合の対数尤度
ll_r = res_probit_0.llf # 制限を課す場合の対数尤度
LR = 2*(ll_ur-ll_r) # LR統計量
dof = 3 # 自由度=制限を課すパラメータの数
1- chi2.cdf(LR, dof)
0.0
1%水準で帰無仮説は棄却できる。
線形確率モデル#
線形確率モデル(Linear Probability Model)を考えるために,関数\(G(.)\)に関して以下を仮定する。
線形確率モデルの利点は,通常のOLS推定が可能だということである。しかし,誤差項は不均一分散となるため以下では不均一分散頑健標準誤差を使う。
res_lin = ols(formula, mroz).fit(cov_type='HC1')
print(res_lin.summary())
OLS Regression Results
==============================================================================
Dep. Variable: inlf R-squared: 0.264
Model: OLS Adj. R-squared: 0.257
Method: Least Squares F-statistic: 62.48
Date: Sat, 20 Sep 2025 Prob (F-statistic): 1.30e-70
Time: 00:35:13 Log-Likelihood: -423.89
No. Observations: 753 AIC: 863.8
Df Residuals: 745 BIC: 900.8
Df Model: 7
Covariance Type: HC1
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 0.5855 0.152 3.846 0.000 0.287 0.884
nwifeinc -0.0034 0.002 -2.233 0.026 -0.006 -0.000
educ 0.0380 0.007 5.229 0.000 0.024 0.052
exper 0.0395 0.006 6.797 0.000 0.028 0.051
expersq -0.0006 0.000 -3.138 0.002 -0.001 -0.000
age -0.0161 0.002 -6.707 0.000 -0.021 -0.011
kidslt6 -0.2618 0.032 -8.237 0.000 -0.324 -0.200
kidsge6 0.0130 0.014 0.962 0.336 -0.014 0.040
==============================================================================
Omnibus: 169.137 Durbin-Watson: 0.494
Prob(Omnibus): 0.000 Jarque-Bera (JB): 36.741
Skew: -0.196 Prob(JB): 1.05e-08
Kurtosis: 1.991 Cond. No. 3.06e+03
==============================================================================
Notes:
[1] Standard Errors are heteroscedasticity robust (HC1)
[2] The condition number is large, 3.06e+03. This might indicate that there are
strong multicollinearity or other numerical problems.
この推定法の問題は,確率の予測値が\([0,1]\)に収まらない場合があることである。この点については以下で確認する。
3つのモデルの比較#
上述の3つのモデルの推定結果のメソッドpredict()は
労働参加の確率\(P(y=1|x)\)の予測値
を返す。
<<注意>>
推定結果には属性
fittedvaluesがあるが,3つのモデルでは以下が返される。\[\hat{\beta}_0+\hat{\beta}_1x\]解釈
線形確率モデル:労働参加の確率\(P(y=1|x)\)の予測値(
predict()と同じ)Logit・Probitモデル:潜在変数(または効用)\(y^*\)の予測値
線形確率モデルでは,労働参加の確率は1以上もしくは0以下になり得る。
no_1 = (res_lin.fittedvalues>1).sum()
no_0 = (res_lin.fittedvalues<0).sum()
print(f'1を上回る予測値の数:{no_1}\n0を下回る予測値の数:{no_0}')
1を上回る予測値の数:17
0を下回る予測値の数:16
LogitモデルとProbitモデルの予測値を図を使って比べてみる。
xx = np.linspace(0,1,100)
y_logit = res_logit.predict()
y_probit = res_probit.predict()
plt.figure(figsize=(4,4)) # 図のサイズ
plt.scatter(y_logit,y_probit, label='comparison')
plt.plot(xx, xx, color='red', linewidth = 2, label='45 degree line')
plt.xlabel('Predicted Probability of Logistic Model')
plt.ylabel('Predicted Probability of Probit Model')
plt.legend()
pass
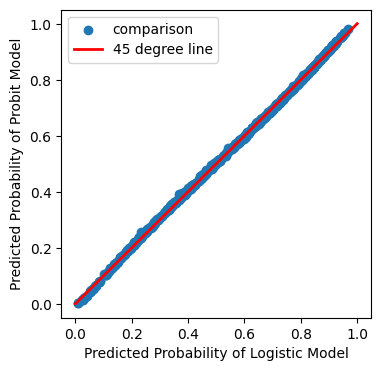
LogitモデルとProbitモデルの予測確率は殆ど変わらない。ではLogitとProbitのどちらをどのような基準で選ぶべきか。Microeconometrics Using Stata (2009)は次を推奨している。
対数尤度(log likelihood)が高い方を選ぶ。
確認するために,それぞれの結果の属性.llfを比べる。
res_logit.llf, res_probit.llf
(-401.7651511343817, -401.30219317389515)
Probitの対数尤度が高いが,殆ど変わらない。この結果は上の図にも反映されている。