重回帰分析#
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
import statsmodels.formula.api as smf
import py4macro
import wooldridge
from numba import njit
from pandas.plotting import scatter_matrix
from scipy.stats import norm, uniform, gaussian_kde, multivariate_normal
from statsmodels.stats.outliers_influence import variance_inflation_factor as vif
# 警告メッセージを非表示
import warnings
warnings.filterwarnings("ignore")
説明#
説明変数が複数の重回帰分析(Multiple Regression)を考える。
\(i=1,2,...n\):観測値のインデックス
\(j=1,2,...k\):説明変数の数
(注意)
\(x_1\)と書く場合,\(x_{i1},x_{i1},...x_{n1}\)を表す(第1番目の説明変数)。
一般的に\(x_j\)と書く場合,\(x_{ij},x_{ij},...x_{nj}\)を表す(第\(j\)番目の説明変数)。
statsmodelsを使う#
推定#
単回帰分析で使った同じデータセットwage1を使い,賃金と教育の関係を再考する。前章と異なる点は,複数の説明変数を導入し重回帰分析をおこなうことである。追加的な説明変数として次の変数を加える。
exper:潜在的な経験年数(=年齢ー最高学歴までの年数ー6)tenure:現在の職場での在職年数
statsmodelsを使う上で単回帰と異なる点は,それぞれの説明変数の前に+を追加するだけである。
まず必要な変数だけを取り出し変数wage1に割り当てる。
wage1 = wooldridge.data('wage1').loc[:,['wage', 'educ', 'tenure', 'exper']]
wooldridge.data('wage1',description=True)
name of dataset: wage1
no of variables: 24
no of observations: 526
+----------+---------------------------------+
| variable | label |
+----------+---------------------------------+
| wage | average hourly earnings |
| educ | years of education |
| exper | years potential experience |
| tenure | years with current employer |
| nonwhite | =1 if nonwhite |
| female | =1 if female |
| married | =1 if married |
| numdep | number of dependents |
| smsa | =1 if live in SMSA |
| northcen | =1 if live in north central U.S |
| south | =1 if live in southern region |
| west | =1 if live in western region |
| construc | =1 if work in construc. indus. |
| ndurman | =1 if in nondur. manuf. indus. |
| trcommpu | =1 if in trans, commun, pub ut |
| trade | =1 if in wholesale or retail |
| services | =1 if in services indus. |
| profserv | =1 if in prof. serv. indus. |
| profocc | =1 if in profess. occupation |
| clerocc | =1 if in clerical occupation |
| servocc | =1 if in service occupation |
| lwage | log(wage) |
| expersq | exper^2 |
| tenursq | tenure^2 |
+----------+---------------------------------+
These are data from the 1976 Current Population Survey, collected by
Henry Farber when he and I were colleagues at MIT in 1988.
被説明変数に対数賃金を使うために、新たな列wage_logを追加する
wage1['wage_log'] = np.log(wage1['wage'])
回帰式では追加の説明変数の前に+を付ける。
formula_1 = 'wage_log ~ educ + tenure + exper'
推計結果を変数res_1に割り当てる。
res_1 = smf.ols(formula_1, data=wage1).fit()
単回帰分析で説明したが,次のコードで結果を表にまとめて表示することができる。(関数print()を使っているが使わなくても同じ情報が表示される。)
print(res_1.summary())
OLS Regression Results
==============================================================================
Dep. Variable: wage_log R-squared: 0.316
Model: OLS Adj. R-squared: 0.312
Method: Least Squares F-statistic: 80.39
Date: Sat, 20 Sep 2025 Prob (F-statistic): 9.13e-43
Time: 00:35:45 Log-Likelihood: -313.55
No. Observations: 526 AIC: 635.1
Df Residuals: 522 BIC: 652.2
Df Model: 3
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
Intercept 0.2844 0.104 2.729 0.007 0.080 0.489
educ 0.0920 0.007 12.555 0.000 0.078 0.106
tenure 0.0221 0.003 7.133 0.000 0.016 0.028
exper 0.0041 0.002 2.391 0.017 0.001 0.008
==============================================================================
Omnibus: 11.534 Durbin-Watson: 1.769
Prob(Omnibus): 0.003 Jarque-Bera (JB): 20.941
Skew: 0.021 Prob(JB): 2.84e-05
Kurtosis: 3.977 Cond. No. 135.
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
属性とメソッド#
推定結果res_1の属性とメソッドはdir()やpy4macro.see()で確認できる。以下ではpy4macro.see()を使う。
py4macro.see(res_1)
.HC0_se .HC1_se .HC2_se .HC3_se
.aic .bic .bse .centered_tss
.compare_f_test() .compare_lm_test() .compare_lr_test() .condition_number
.conf_int() .conf_int_el() .cov_HC0 .cov_HC1
.cov_HC2 .cov_HC3 .cov_kwds .cov_params()
.cov_type .df_model .df_resid .diagn
.eigenvals .el_test() .ess .f_pvalue
.f_test() .fittedvalues .fvalue .get_influence()
.get_prediction() .get_robustcov_results() .info_criteria() .initialize()
.k_constant .llf .load() .model
.mse_model .mse_resid .mse_total .nobs
.normalized_cov_params .outlier_test() .params .predict()
.pvalues .remove_data() .resid .resid_pearson
.rsquared .rsquared_adj .save() .scale
.ssr .summary() .summary2() .t_test()
.t_test_pairwise() .tvalues .uncentered_tss .use_t
.wald_test() .wald_test_terms() .wresid
単回帰分析と同様に、係数の推定値は属性.paramsで取得できる。
res_1.params
Intercept 0.284360
educ 0.092029
tenure 0.022067
exper 0.004121
dtype: float64
res_1はSeriesなので、インデックスを使ってeducの係数だけを取り出す場合は次のようにする。
res_1.params.iloc[1]
0.09202898676928332
次に,メソッドpredict()を使って予測値を計算してみよう。次の例では,educ, tenure, experの平均値でのnp.log(wage)を計算する。
wm = wage1.mean() # 変数の平均の計算
wm
wage 5.896103
educ 12.562738
tenure 5.104563
exper 17.017110
wage_log 1.623268
dtype: float64
wmはSeriesなので、変数の行ラベルを使いwm['educ']でeducの平均値だけを取り出すことができる。
wm['educ']
12.562737642585551
predict()に渡す引数としては,説明変数の辞書を作るのが一番簡単であろう。
z = {'educ':wm['educ'],
'tenure':wm['tenure'],
'exper':wm['exper']}
res_1.predict(z)
0 1.623268
dtype: float64
3つの変数が平均値を取る場合の平均時給の対数値は約1.62である。
複数の予測値を計算するには、辞書の値にlistやarrayを書き込めば良い。次の例では、tenureとexperを平均値に固定し、educを平均値、平均値-1、平均値+1に変化させて予測値を計算している。
educ_mean = wm['educ']
tenure_mean = wm['tenure']
exper_mean = wm['exper']
z2 = {'educ':[educ_mean-1, educ_mean, educ_mean+1],
'tenure':[tenure_mean]*3,
'exper':[exper_mean]*3}
educ_return = res_1.predict(z2)
educ_return
0 1.531239
1 1.623268
2 1.715297
dtype: float64
3つの変数が平均の値を取る場合,平均賃金の対数値は1.623268であり,上の計算と同じになることが確認できる。教育年数が1年減少すると予測値は1.531239であり,教育年数が1年増えると予測値は1.715297となる。この結果を使い,教育年数が一年変化する場合の影響を計算してみよう。まず教育年数が1年減少すると場合を計算しよう。
educ_return[0]-educ_return[1]
-0.09202898676928317
次に教育年数が1年増える場合を計算しよう。
educ_return[2]-educ_return[1]
0.0920289867692834
これらの数字の絶対値は同じである。この結果は偶然ではない。他の要因を固定し教育年数が1年変化(減少もしくは増加)した場合,平均時給の対数値がどれだけ変化したかを計算している。これは正しく教育の収益率である。この点を数式で確認するために,変数\(x\)の値が小さい場合(例えば,0.02),次の近似が成立することを思い出そう。
また教育年数が\(h\)の場合の平均時給を\(w(h)\)としよう。教育年数が一年増えた場合の教育の収益率は\(\dfrac{w(h+1)-w(h)}{w(h)}\)となり,(1)を使うと次のように書くことができる。
最後の等号が上の計算で使った式である。\(h+1\)を\(h-1\)に変えると教育年数が1年減少した場合を考えることができる。
もう一点付け加えるために,上の回帰分析の変数educの係数の解釈を思い出そう。教育年数が一年増えた場合,平均賃金の対数値はどれだけ変化するかを示しており,教育の収益率を表している。従って,ここで計算した値と同じになるはずである。
res_1.params['educ']
0.09202898676928332
(コメント)
predict()の引数を省略すると予測値を返す属性.fittedvaluesと同じ値を返す。それを確かめるために次のコードを評価してみる。
( res_1.predict() == res_1.fittedvalues ).all()
True
コードの説明
res_1.predict() == res_1.fittedvaluesの意味res_1.predict()とres_1.fittedvaluesはSeriesを返すので,==で比較することにより,それぞれの対応する要素の値が等しければTrue,異なればFalseになるSeriesを返す。
( res_1.predict() == res_1.fittedvalues )の()は、その中のコードを先に実行することを指定する(数学の()と同じ)。all()は返されたSeriesの値が全てTrueである場合はTrueを、1つでもFalseがあればFalseを返す。
Trueが返されているので、値は全て同じだと確認できた。
変数の変換#
上の重回帰分析では,回帰式のwageを対数化した変数を新たに作成し計算を行なっているが、回帰式の中で変数の変換を直接指定することもできる。以下で説明する方法は被説明変数・説明変数の両方に使用可能である。
Numpyの関数を使う方法#
Numpyの対数関数を使って,回帰式の中で直接書き換えることができる。wageを対数化する例を考える。
formula_2 = 'np.log(wage) ~ educ + tenure + exper'
res_2 = smf.ols(formula_2, data=wage1).fit()
res_2.params
Intercept 0.284360
educ 0.092029
tenure 0.022067
exper 0.004121
dtype: float64
I()を使う方法#
次にexperの二乗を回帰式に入れるケースを考えよう。この場合、np.square(exper)でも良いが、I()の()の中に直接式を書くことが可能となる。
formula_3 = 'np.log(wage) ~ educ + tenure + exper + I(exper**2)'
res_3 = smf.ols(formula_3, data=wage1).fit()
res_3.params
Intercept 0.198345
educ 0.085349
tenure 0.020841
exper 0.032854
I(exper ** 2) -0.000661
dtype: float64
この方法であれば、Numpyに無い関数も直接書くことができる。
defを使う方法#
より複雑な関数であればdefを使い、関数を定義し、それを回帰式の中で使う方が良いかも知れない。experの二乗を回帰式に入れるケースを考えよう。
def myfunc(x):
return x**2
formula_4 = 'np.log(wage) ~ educ + exper + tenure + myfunc(exper)'
res_4 = smf.ols(formula_4, data=wage1).fit()
res_4.params
Intercept 0.198345
educ 0.085349
exper 0.032854
tenure 0.020841
myfunc(exper) -0.000661
dtype: float64
Q()について#
Q()は変数の変換に使うわけではないが、その用途を覚えておくと役に立つだろう。
Pythonには予約語(reserved words)と呼ばれるものがり、変数名には使えない。以下がその例である。
defとreturn:関数を定義する場合に使うforとwhile:ループに使うimportとfrom:パッケージのインポートifとelifとelse:if文に使う
またDataFrameの列ラベルに予約語を文字列として使うことも避けるべきであろう。しかし、どうしても使う場合もあるかもしれない(例えば、他のプログラム用に作成されてデータを読み込む場合)。だが、予約語をそのまま回帰式に書くとエラーが発生する。その際に役に立つのがQ()である。例えば、dfというDataFrameに「利子率」の列があり,列ラベルとしてreturnが設定されているとしよう。Q()の引数としてreturnを文字列で書くことにより、通常どおりのコードを書くことができる。
formula = 'Q("return") ~ X
res = ols(formula, data=df).fit()
また123goのように数字から始まる列ラベルもあるかもしれない。この場合も回帰式でそのまま使うとエラーが発生するが、Q()の引数として文字列で指定すればが使えるようになる。
formula = 'Q("return") ~ X + Q("123go")'
res = ols(formula, data=df).fit()
係数の解釈#
次の推定式を考えよう。
<解釈1:Ceteris Paribus>
\(x_1\)以外の変数を固定して\(x_1\)だけを少しだけ変化させる。これにより,\(y\)に対する\(x_1\)の影響だけを考えることが可能となり、次の記号で表す。
ここで
\(\Delta x_1=x_1\)の変化(1単位の変化と解釈する)
\(\Delta y=y\)の変化
\(\beta_1\)は、\(x_1\)が一単位増加した場合の\(y\)の変化を示している。重要な点は,\(x_1\)以外の変数は固定されていることである。これをCeteris Paribus (ラテン語; “other things being equal”という意味)と呼ぶ。
<解釈2:影響の除去>
まず\(y\)と\(x_1\)の関係を捉える\(\hat{\beta}_1\)を考えよう。もし推定式に\(x_2\)と\(x_3\)が入っていなければ,\(\hat{\beta}_1\)は\(x_2\)と\(x_3\)の影響を拾うことになる(\(x_1\)が\(x_2\)と\(x_3\)のそれぞれと完全に無相関でない場合)。即ち,\(x_2\)と\(x_3\)が入ることにより,\(\hat{\beta}_1\)はこれらの変数の影響を「除去」した後に残る\(y\)と\(x_1\)の関係を捉えていると考えることができる。同じように,\(\hat{\beta}_j\)は\(j\)以外の説明変数の影響を取り除いた後に残る\(y\)と\(x_j\)の関係を示している。
wage1を使い以下を推定しよう。
formula_1a = 'wage ~ educ + tenure + exper'
res_1a = smf.ols(formula_1a, data=wage1).fit()
res_1a.params
Intercept -2.872735
educ 0.598965
tenure 0.169269
exper 0.022340
dtype: float64
tenureとexperを固定して,educを一単位増加させるとしよう。その効果は
即ち,教育期間が一単位(ここでは一年)増えると賃金は0.599ドル増加することを示している。
次にformula_1の回帰式を使って推定したres_1を考えよう。この場合,
対数の性質を使い左辺は次のように書き換えることができる。
ここで,\(\%\Delta\text{wage}=\)%で表した
wageの変化を意味する((2)を参照)。従って,教育期間が一単位(ここでは一年)増えると賃金は約9.2%増加することを示している。
ガウス・マルコフ定理#
母集団回帰式と標本回帰式#
今までは回帰式に基づいてPythonを使い係数の推定方法を説明したが,ここではOLS推定量の望ましい性質とはなにか,望ましい性質の条件はなにかを考える。そのために,まず母集団回帰式と標本回帰式について説明する。
計量経済学では,データを使い経済理論(経済学的な考え) に基づいた仮説を検証する。例として「消費は家計の所得\(x_1\)が高くなると増え,子どもの数\(x_2\)とも正比例する」という仮説を考えよう。所得と子どもの数に依存する消費の部分だけを\(y^*\)と書くと,一般型の消費関数は\(y^*=f\left(x_1,x_2\right)\)となる。更に,線形を仮定すると次式となる。
例えば,所得30万円,子ども2人の家計の場合、消費は\(\beta_0+\beta_1\cdot\left(\text{30万円}\right)+\beta_2\cdot\left(\text{2人}\right)\)となる。所得 \(x_1\)が変化すると消費\(y^*\)も変化することが分かる。このことは\(\beta_2=0\)の単回帰の場合(消費が子供の数に依存しない場合)を考えればもっと分かりやすいだろう。その場合,(式1)は
となり,横軸に\(x_1\),縦軸に\(y^*\)を置く図では右上がりの直線となる。
(式1)は平均の家計の行動を表していると考えることができる。従って,同じ所得と子どもの数の家計でも好み等の要因が違うと消費に違いがでる。その違いを(平均ゼロの)誤差項\(u\)として捉えると,全ての家計の消費 \(y\)は次式で表すことができる。
\(y^*\):平均の家計の消費であり,\(x_1\)と\(x_2\)のみに依存する部分
\(u\):平均の家計と異なる家計の消費であり,平均家計との違いを捉える部分
(式1)を(式2)に代入すると
となる。この式は仮説に基づいた関係式であり,母集団回帰式と呼ばれる。また(式3)を使い\(x_1\)と\(x_2\)を所与として期待値を計算すると次式を得る。
これは「\(x_1\)と\(x_2\)を所与とする」という条件の下での期待値なので条件付き期待値(conditional expectations)と呼ばれる。この式は,\(y\)の条件付き期待値は母集団回帰式の\(x_1\)と\(x_2\)に依存する部分である\(y^*\)と等しいことを示している。即ち,(式1)は母集団で平均として成立する母集団回帰線を表している。
Note
母集団回帰式(式3)は理論的な仮定に基づいて導出したため,それが正しいかどうかは事前に分からない。従って,経済理論に基づき母集団回帰式の妥当性を検討する必要がある。
母集団パラメータ\(\beta_j\), \(j=0,1,2\)と誤差項\(u\)は観測できない。
母集団回帰式(式3)が成立するという仮定のもとで母集団パラメータ\(\beta_j\),\(j=0,1,2\)を推定することになる。そのためには,
\(\left\{y_i,x_{i1},x_{i2}\right\}\), \(i=1,2,..,n\) の標本を収集する。
次式に重回帰分析の手法を適用しOLS推定値を計算する。
\[y_i=\beta_0+\beta_1x_{i1}+\beta_2x_{i2}+u_i,\qquad i=1,2,..,n\qquad{(式4)}\]
母集団回帰式(式3)と区別するために,この式には添え字\(i\)があり標本回帰式と呼ぶ。
Note
通常,標本の大きさは母集団のそれよりも小さい。従って,パラメータのOLS推定値\(\hat{\beta}_j\)には誤差が発生する。即ち,必ずしも\(\hat{\beta}_j=\beta_j\), \(j=0,1,2\)とはならない。
一方で,上で述べたようにOLS推定量には何らかの「望ましい性質」がある。
「望ましい性質」の前提となる条件は何なのか?
OLS推定量の「望ましい性質」とは何なのか?
以下では1から考える。
仮定と望ましい性質#
仮定1:Linear in Parameters(母集団回帰式の線形性)
母集団のモデルは次式のようにパラメータに関して線形である。
\[ y=\beta_0+\beta_1x_1+\beta_2x_2+\cdots+\beta_kx_k+u \]\(y=\beta_0+\beta_1x_1+\beta_2x_1^2\)は線形性を満たす。
\(y=\beta_0+\dfrac{\beta_1}{1+\beta_2x_1}+\beta_3x_2\)は線形性を満たさない。
仮定2:Random Sampling(標本の無作為抽出)
無作為に\(\left\{y_i,x_{i1},,x_{i2},...,,x_{ik}\right\}\), \(i=1,2,...,n\)が抽出される。
多くの横断面データでは成立すると考えられている(時系列データでは満たされない場合が多い)。
この仮定により
\[\text{Corr}\left(u_i,u_j|X\right)=0,\;i\neq j,\qquad X=\{x_1,x_2,...x_k\}\]となる。つまり,説明変数\(X\)を所与として\(u_i\)と\(u_j\)は何の関係もないという意味である。
仮定3:No Perfect Collinearity(母集団回帰式の説明変数の非完全多重共線性)
説明変数\(x_j\)が他の説明変数の完全な線形結合(例えば,\(x_2=1+2x_1\)や\(x_1=x_2+5x_4\))として表すことができないという意味である。もしこの仮定が満たされなければ\(x_j\)は何の追加的な情報を持たなくなる。
定数項以外の説明変数が全く変化しないことも排除している(例えば,\(x_j=3\))。このような変数は定数項の単なるスケールアップ・バージョンであり,追加的な情報はない。(定数項以外の説明変数は変化してこそ\(y\)を説明できる。)
仮定4:Zero Conditional Mean(母集団回帰式の誤差項の条件付き期待値は
0)\[\text{E}\left(u|X\right)=0,\qquad X=\{x_1,x_2,...x_k\}\]\(X\)はランダム変数であるが,\(X\)を所与とすると\(u\)の平均はゼロになるという仮定である。即ち,ランダム変数である\(X\)がどのような値を取ったとしても,\(u\)の平均は0だということである。\(X\)は\(u\)に対して何の情報も影響力も全くないため,\(X\)と\(u\)が線形・非線形な関係が無いことを意味する。即ち,\(X\)と\(u\)は独立性を満たす。
\(X\)はランダム変数であるため,\(X\)が変化する場合の\(\text{E}\left(u|X\right)\)の平均を考えることができる。即ち,\(\text{E}\left[\text{E}\left(u|X\right)\right]=0\)である。外側の\(E\)は\(X\)に対する期待値演算子であり,\(E\)が入れ子になっているのでiterated expectationsと呼ばれる。\(X\)がどのような値を取ったとしても仮定4のもとでは\(0\)になるので等号が成立することになる。更に,\(X\)に対しての期待値が付け加えられているので,\(X\)を省いて\(\text{E}\left[\text{E}\left(u|X\right)\right]=\text{E}(u)=0\)となる。\(X\)の条件をつけなくとも\(u\)の平均はゼロになることを示している。
\(X\)と\(u\)には線形の依存関係がないので\(\text{Cov}(X,u)=0\)が成立する。しかし,\(\text{Cov}(X,u)=0\)(無相関)は\(\text{E}\left(u|X\right)=0\)(独立性)を意味しないことを覚えておこう。
仮定1〜4の下で母集団パラメータのOLS推定量は不偏性(unbiasedness)を満たす。
(解釈)
標本の大きさが\(n\)の標本を使い回帰分析をおこない\(\hat{\beta}_j\)を得たとしよう。さらに同じ標本の大きさ\(n\)の異なる標本を使い回帰分析を合計\(N\)回おこない\(\hat{\beta}_j\)を計算したとしよう。不偏性とは\(N\)が十分に大きい場合(\(N\rightarrow\infty\)),\(N\)個ある\(\hat{\beta}_j\)の平均は\(\beta_j\)と等しいという性質である。
(注意点)
この結果は標本の大きさ\(n\)に依存しない。即ち,大標本(\(n\rightarrow\infty\))である必要はない。むしろ小標本(\(n<\infty\))で重要視される小標本特性(データが少ない場合の特性)と考えるべきである。
仮定5:Homoskedasticity(均一分散; 母集団回帰式の説明変数は誤差項の分散に影響を与えない)
仮定1〜5をガウス・マルコフ仮定(横断回帰分析のGM仮定)と呼び,この仮定の下では以下が成立する。
誤差分散の推定量 \(\hat{\sigma}^2\)の平均は母集団の値と等しい(誤差分散の不偏推定量)。
\[ \text{E}\left(\hat{\sigma}^2\right)=\sigma^2 \]ここで,\(\hat{\sigma}^2=\dfrac{\sum_{i=1}^n\hat{u}_i^2}{n-k-1}=\dfrac{SSR}{n-k-1}\) であり,\(\hat{u}_i=y_i-\hat{y}_i\)はOLS残差であり,\(SSR\)は残差の二乗平方和。\(\hat{\sigma}\)にはさまざまな呼称があり,the Standard Error of Regression, the Standard Error of the Estimate, the Root Mean Squared Errorがある。
OLS係数の(標本)分散の推定量(\(\sigma^2\)に\(\hat{\sigma}^2\)が代入されている)
\[ \widehat{\text{Var}}\left(\hat{\beta}_j\right) =\dfrac{\hat{\sigma}^2}{SST_j\left(1-R_j^2\right)} =\dfrac{1}{n-1}\cdot \dfrac{\hat{\sigma}^2}{\text{Var}(x_j)}\cdot \dfrac{1}{1-R_j^2} \]ここで,\(\text{Var}(x_j)=(n-1)^{-1}\sum_{i=1}^n\left(x_{ij}-\overline{x}_j\right)\)であり,\(R_j^2\)は\(x_j\)を他の全ての説明変数に回帰分析する際の決定係数である。 \(\widehat{\text{Var}}\left(\hat{\beta}_j\right)\)はOLS推定量\(\hat{\beta}_j\)の精度を捉え,低ければより高い精度を意味する。(「なぜ分散?」と思う場合は前章のシミュレーション1で,標本のランダム抽出を行うたびに,\(\hat{\beta}\)の値が変わったことを思い出そう。)
パラメータの分散の推定量の式から次のことが分かる。
\(\dfrac{1}{n-1}\): 標本の大きさが大きくなると\(\hat{\beta}_j\)の精度を高める。
\(\dfrac{\hat{\sigma}^2}{\text{Var}(x_j)}\): 残差の分散に対して説明変数\(x_j\)の分散が大きければ,\(\hat{\beta}_j\)の精度を高める。
\(R_j^2\)は多重共線性が高くなると大きくなる。従って,多重共線性が高いと\(\hat{\beta}_j\)の精度を低下させる。
\(\widehat{\text{Var}}\left(\hat{\beta}_j\right)\)のルートはOLS推定量の標準誤差と呼ぶ(パラメータの推定値の標準偏差)。
この結果は推定結果の検定や信頼区間を計算する際に必要となる。
ガウス・マルコフ定理(望ましい性質)
GM仮定1〜5のもとでOLS推定量はB.L.U.E(Best Linear Unbiased Estimators; 最良不偏推定量)
不偏性(unbiasedness): \(\text{E}\left(\hat{\beta}_j\right)=\beta_j\)
効率性(efficiency): \(\text{Var}\left(\hat{\beta}_j\right)\)は線形推定値の中で最小
上の回帰分析結果res_1を使って,ここで定義した推定値の取得方法を説明する。
誤差分散\(\hat{\sigma}^2\)の推定値
res_1の属性.scaleで取得可能。
res_1.scale
0.19435933207482126
SSR = res_1.ssr # 残差の二乗平方和
n = res_1.nobs
k = res_1.df_model
SSR/(n-k-1)
0.19435933207482126
Note
上の計算に属性.ssrが出てくる。インターネットでstatsmodels result検索してみよう。Googleの検索結果の一番上のサイトは該当するstatsmodelsマニュアルとなっており、ウェブページの下の方に行くと.ssrを見つけることができるはずだ。
パラメータの標準誤差 \(\text{se}\left(\hat{\beta}_j\right)\)
res_1のメソッド.bseで取得可能。
res_1.bse
Intercept 0.104190
educ 0.007330
tenure 0.003094
exper 0.001723
dtype: float64
パラメータの標準誤差は\(se\)(standard error)だが属性はbseとなっている。これはパラメータを\(b\)で表しており,\(b\)の\(se\)として覚えれば良いだろう。
「手計算」#
係数の推定値#
statsmodelsは非常に優れたパッケージであり,複雑な計算を簡単なコードで実行してくれる。しかしここではNumpyの関数を使い,重回帰分析における推定値を「手計算」で求める。目的は2つある。第1に,statsmodelsの裏でどのような計算が行われているかを理解する。第2に,今後シミュレーションをおこなうが,「手計算」のコードを使うとNumbaを使い計算速度を格段とアップすることが可能となる。
次の回帰式を考えよう。
これを行列式で表すと次のようになる。
更に簡単に書くと
となる。これを使うと\(B\)の推定量は
で与えられる。以下ではシミュレーションを使い式(*)の計算に使うコードを説明する。
まず母集団回帰式の係数と標本の大きさを設定する。
b0 = 1 # 定数項
b1 = 2 # x1の係数
b2 = 3 # x2の係数
n = 30 # 標本の大きさ
母集団からの標本を生成する。
x1 = np.random.normal(loc=4.0, scale=2.0, size=n) # (1)の説明
x2 = np.random.uniform(low=1.0, high= 10.0, size=n) # (2)の説明
u = np.random.normal(loc=0, scale=1.0, size=n) # (1)の説明
y = b0 + b1*x1 + b2*x2 + u
c = np.ones(n) # (3)の説明
Numpyには乱数用のモジュールrandomがあり,normalは標準正規分布からの乱数を発生させる関数である。引数の設定方法はscipy.statsのnorm.rvs()と同じである。x1は平均4.0と標準偏差2.0の正規分布に従うことがわかる。同じ
np.randomにあるuniformは[0,1)の一様分布から乱数を発生させる関数である。scipy.statsのuniform.rvsと同じ役割を果たすが,引数の設定が異なる。lowは最小値,highは最大値を指定する。Numpyの関数であるones()は全ての要素が1になる\((n\times 1)\)のarrayを生成する。
式(*)を使い推定値を計算しよう。まずNumpyの関数stackを使いXを作成する。
X = np.stack([c,x1,x2],axis=1)
X.shape
(30, 3)
ここでの引数axis=1はc,x1,x2を縦ベクトルとして横方向につなぎあわせることを指定している。XはNumpyのarrayであり\((30\times 3)\)の行列となっている。式(*)を次のコードで計算する。
bhat = np.linalg.inv((X.T)@X)@(X.T)@y
bhat
array([0.77857781, 1.99360747, 3.04477935])
左からb0,b1,b2の推定値となる。上のコードを簡単に説明する。
linalgはNumpyの線形代数のパッケージであり,invは逆行列を計算するための関数Tは転置行列の属性@は行列の積
bhatを計算した1行コードは、定数項以外に2つの説明変数を想定している。実は、定数項以外の説明変数の数が1でも20でも同じコードが使える。ただ、必要なのはXを説明変の数に合わせて作成することである。
statsmodelsを使い推定値が同じであることを確認する。
df_check = pd.DataFrame({'Y':y,'X1':x1,'X2':x2})
res_check = smf.ols('Y ~ X1 + X2', data=df_check).fit()
res_check.params
Intercept 0.778578
X1 1.993607
X2 3.044779
dtype: float64
推定値の標準誤差#
次に推定値の標準誤差を考えよう。推定値の分散共分散行列は次式で表される。
\(\sigma_e^2\)は次の2つの式から求められる。
ここで\(e\)は残差,SSR(Residual Sum of Squares)残差変動の平方和を指しており,\(k\)は定数項以外の説明変数の数である。係数の推定値の標準誤差は\(\text{Var}\left(\hat{B}\right)\)の対角成分の平方根で与えられる。実際に計算してみよう。
e = y.T-X@bhat.T
SSR = e@e.T
SSR
30.44616426936204
この値はres_checkの属性.ssrと同じことが確認できる。
res_check.ssr
30.446164269362
次に\(\hat{\sigma}_e^2\)を計算しよう。
sigma_e2 = SSR/(n-1-2)
sigma_e2
1.1276357136800756
この値もres_checkの属性.scaleから取得できる。
res_check.scale
1.127635713680074
次に\(\text{Var}\left(\hat{B}\right)\)を計算し変数bvarに割り当てる。
bvar = sigma_e2 * np.linalg.inv(X.T@X)
bvarは3X3の行列になっており,その対角成分はメソッド.diagonal()で抽出できる。その平方根が推定値の標準誤差となる。
np.sqrt(bvar.diagonal())
array([0.56007079, 0.08348779, 0.06948103])
statsmodelsの結果と比べてみよう。
res_check.bse
Intercept 0.560071
X1 0.083488
X2 0.069481
dtype: float64
同じ結果である。
シミュレーション:不偏性#
不偏性をシミュレーションで考える。
標本をランダム抽出するたびに\(\hat{\beta}_j\), \(j=0,1\)は異なる値を取るが,標本抽出を繰り返し\(\hat{\beta}_j\)の平均を計算すると真の値と「等しい」ことを示す。
シミュレーションでは上で使った同じ回帰式を使う。
シミュレーションの関数を作成するが,パラメータの推定値の計算にはstatsmodelsを使わずに,Numpyの関数を使い「手計算」とし高速化パッケージNumbaを使う。単回帰分析のシミュレーションと同じように、使い方は簡単でデコレーターと呼ばれる@njit(又は@jit)を関数の上に加えるだけである。
次の関数の引数:
n:標本の大きさN:シミュレーションの回数(標本数と考えても良い)b0:定数項(デフォルトは1.0と設定)b1:スロープ係数(デフォルトは2.0と設定)b2:スロープ係数(デフォルトは3.0と設定)
次の関数の返り値:
b0、b1、b2のN個の推定値がそれぞれ格納されているNumpyのarray
@njit # 計算の高速化
def sim_unbias(n, N, b0=1.0, b1=2.0, b2=3.0):
# N個の0からなるarrayであり、0を推定値と置き換えて格納する
b0hat_arr = np.zeros(N)
b1hat_arr = np.zeros(N)
b2hat_arr = np.zeros(N)
c = np.ones(n) # 定数項
for i in range(N): # N 回のループ
# 標準正規分布
u = np.random.normal(loc=0, scale=1.0, size=n)
# 平均4.0,標準偏差2.0の正規分布
x1 = np.random.normal(loc=4, scale=2.0, size=n)
# [1,10)の一様分布。`low=`,`high=`を付け加えるとエラーが発生する。
x2= np.random.uniform(1.0, 10.0, size=n)
y = b0 + b1*x1 + b2*x2 + u # 被説明変数の生成
X = np.stack((c,x1,x2),axis=1) # 説明変数の行列
bhat = np.linalg.inv((X.T)@X)@(X.T)@y # OLS推定
b0hat_arr[i] = bhat[0] # 上のarrayに推定値を代入する
b1hat_arr[i] = bhat[1]
b2hat_arr[i] = bhat[2]
return b0hat_arr, b1hat_arr, b2hat_arr
標本の大きさは30、シミュレーションの回数は100_000に設定し、結果はb0hat, b1hat, b2hatに割り当てる。
b0hat, b1hat, b2hat = sim_unbias(n=30, N=100_000)
推定値の平均を計算してみよう。
print('b0:', b0hat.mean(),
'\nb1:', b1hat.mean(),
'\nb1:', b2hat.mean())
b0: 1.001170839567358
b1: 1.9996302408793953
b1: 3.00007293675821
平均は真の値と全く同じではないが,十分に近い値である。即ち,不偏性が満たされている。標本数Nを増加させるとより真の値に近づくことになる。
次に、OLS推定量\(\hat{\beta}_1\)の分布を図示しよう。
plt.hist(b1hat,bins=30)
plt.axvline(x=b1,color='red')
pass
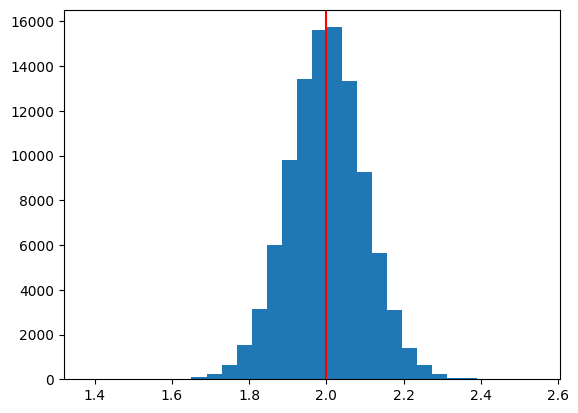
b1の真の値2.0を中心に概ね左右対象に分布していることが分かる。
次に分布(ヒストグラム)のカーネル密度推定をおこなうために,scipy.statsにあるgaussian_kdeを使う。
x=np.linspace(1.5,2.5,100) # 図を作成するために1.5から2.5までの横軸の値を設定
kde_model=gaussian_kde(b1hat) # カーネル密度推定を使いb1hatの分布を推定
plt.plot(x, kde_model(x)) # 誤差項の分布をプロット
plt.axvline(x=b1,color='red') # 母集団のパラメータ
pass
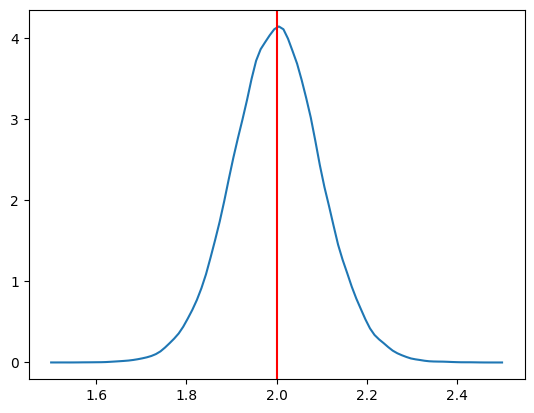
2つの図を重ねる。
(注意)ヒストグラムの縦軸は頻度である。一方,カーネル密度推定の場合,曲線の下の面積が1になるように縦軸が設定されている。ヒストグラムの縦軸をカーネル密度推定に合わせるためにdensity=Trueのオプションを加える。
x=np.linspace(1.5,2.5,100)
kde_model=gaussian_kde(b1hat)
plt.plot(x, kde_model(x))
plt.hist(b1hat,bins=30, density=True)
plt.axvline(x=b1,color='red')
pass
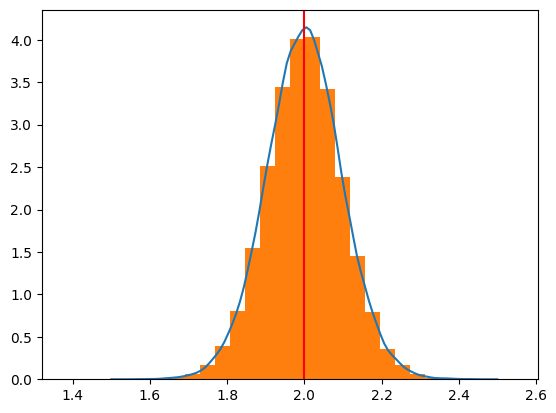
<Give it a try!>
標本の大きさ
nを30、100、500の3つのケースでシミュレーションをおこない、それぞれのカーネル密度推定を重ねて1つの図を作成しなさい。\(\hat{\beta}_0\)と\(\hat{\beta}_2\)の分布も図示しなさい。
nを変化させて違いを確かめなさい。Nを変化させて違いを確かめなさい。
シミュレーション:多重共線性#
説明#
多重共線性が高くなると,パラメータの推定値の精度が低下する(即ち、パラメータの標準誤差\(\text{se}\left(\hat{\beta}_j\right)\)が大きくなる)。この点を確認するためにパラメータの分散の推定値にある
を利用する。これは
分散拡大因子(variance inflation factor)
と呼ばれる。以下ではvifと呼ぶ。この値が10以上になる説明変数どうしを使うと多重共線性の可能性が高いといわれる。
例として回帰分析res_1を考える。
方法1:手計算#
まず説明変数だけから構成されるDataFrameを作成する。
wage1_vif = wage1.loc[:,['educ','tenure','exper']]
corr()は相関係数を返すメソッドであり,そこから.to_numpy()を使いデータをNumpyのarrayとして取り出す。
mc = wage1_vif.corr().to_numpy()
上でも使った
linalg.inv()は、NumPyにあるlinalgサブパッケージの関数であり、逆行列を返す。diagonal()は対角成分を返すメソッドであり,それがvifである。
vif_manual = np.linalg.inv(mc).diagonal()
vif_manual
array([1.11277075, 1.34929556, 1.47761777])
変数名と一緒に表示するために次のようにSeriesとして表示する。
pd.Series(vif_manual, index=wage1_vif.columns)
educ 1.112771
tenure 1.349296
exper 1.477618
dtype: float64
次に上の計算を関数にまとめる。
def my_vif(dataframe):
mc = dataframe.corr().to_numpy()
vif = np.linalg.inv(mc).diagonal()
return pd.Series(vif_manual, index=dataframe.columns)
my_vif(wage1_vif)
educ 1.112771
tenure 1.349296
exper 1.477618
dtype: float64
方法2:statsmodels#
statsmodelsにあるvariance_inflation_factorを使いvifを計算することもできる。
必ず定数項を含む説明変数だけから構成されるDataFrameを作成する。
wage1_vif['Intercept'] = 1.0
for i in range(len(wage1_vif.columns)-1): # 定数項は無視するために-1
name = wage1_vif.columns[i]
vif_val = vif(wage1_vif.to_numpy(), i)
print(f'{name : <10}{vif_val}')
educ 1.1127707502838837
tenure 1.3492955605611774
exper 1.4776177726317783
定数項は考えなくて良い。
(コードの説明)
f-stringを使っている。{name : <10}は、nameの値を代入し、10という幅の中で左寄せしている。{vif_val}は、vif_valの値を代入している。
シミュレーション#
シミュレーションをおこない、多重共線性によりOLS推定量の標準誤差が上昇し推定量の精度が損なわれることを確認する。
シミュレーションでは以下の回帰式を使う。
母集団の係数の値を以下のように設定する
\(\beta_0=1.0\)
\(\beta_1=2.0\)
\(\beta_2=3.0\)
シミュレーションの関数を作成する。
引数
n:標本の大きさN:標本数(ループの回数)m:2つの説明変数の共分散b0:定数項(デフォルトは1.0と設定)b1:スロープ係数(デフォルトは2.0と設定)b2:スロープ係数(デフォルトは3.0と設定)
返り値
\(\hat{\beta}_i\),\(i=0,1,2\)の推定値のリスト
(コメント)
@njitを使いたいところだが,Numpyのrandom.multivariate_normal()がNumbaに対応していないためscipy.statsのmultivariate_normal.rvs()を使う。np.random.normal()を使って二変量正規分布からの値とする方法もあるが,ここでは簡単化を重視する。olsは係数の推定値だけではなく他の多くの統計値も自動的に計算するため一回の計算に比較的に長い時間を要する。計算の速度を少しでも早めるために下の関数の中ではolsは使わずNumpyの関数を使いOLS推定値を計算する。
def sim_multi(n, N, m, b0=1.0, b1=2.0, b2=3.0): # n=標本の大きさ, N=標本数, m=共分散
# 2つのx1,x2の共分散を設定
rv_mean = [4, 1] # x1, x2の平均
# x1, x2の共分散行列
rv_cov = [[1.0, m], # 全ての変数の分散は1(対角成分)
[m, 1.0]] # Cov(x1,x2)=m
# 推定値を入れる空のarray
b0hat_arr = np.zeros(N)
b1hat_arr = np.zeros(N)
b2hat_arr = np.zeros(N)
c = np.ones(n) # 定数項
for i in range(N): # N 回のループ
# x1, x2の値の抽出
rv = multivariate_normal.rvs(rv_mean, rv_cov, size=n) # x1, x2,をnセット抽出
x1 = rv[:,0] # 説明変数
x2 = rv[:,1] # 説明変数
u = np.random.randn(n) # 標準正規分布
y = b0 + b1*x1 + b2*x2 + u # 説明変数
X = np.stack((c,x1,x2),axis=1) # 説明変数の行列
bhat = np.linalg.inv((X.T)@X)@(X.T)@y # OLS推定
b0hat_arr[i] = bhat[0] # b0hat_arrへの追加
b1hat_arr[i] = bhat[1] # b1hat_arrへの追加
b2hat_arr[i] = bhat[2] # b2hat_arrへの追加
return b0hat_arr, b1hat_arr, b2hat_arr # 返り値の設定
シミュレーションの開始
# 多重共線性が弱いケース
b0hat_weak, b1hat_weak, b2hat_weak = sim_multi(30, 10_000, m=0.1)
# 多重共線性が強いケース
b0hat_strong, b1hat_strong, b2hat_strong = sim_multi(30, 10_000, m=0.9)
\(\hat{\beta}_1\)の分布の図示
xx=np.linspace(0.5,3.5,num=100) # 図を作成するために横軸の値を設定
# 多重共線性が弱いケース
kde_model_weak=gaussian_kde(b1hat_weak) # OLS推定量のカーネル密度関数を計算
# 多重共線性が強いケース
kde_model_strong=gaussian_kde(b1hat_strong)
plt.plot(xx, kde_model_weak(xx), 'g-', label='Low VIF') # OLS推定量の分布プロット
plt.plot(xx, kde_model_strong(xx),'r-', label='High VIF') # IV推定量の分布プロット
plt.axvline(x=b1,linestyle='dashed')
plt.ylabel('Kernel Density') # 縦軸のラベル
plt.legend() # 凡例
pass
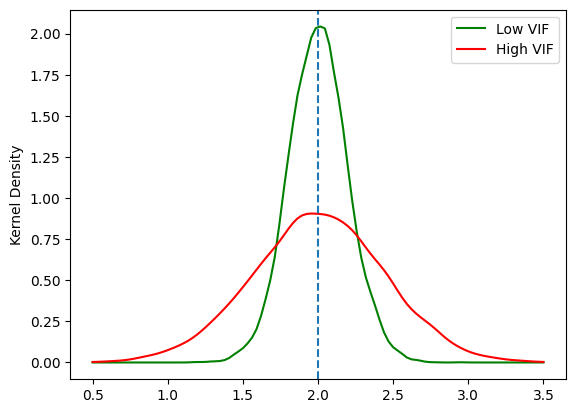
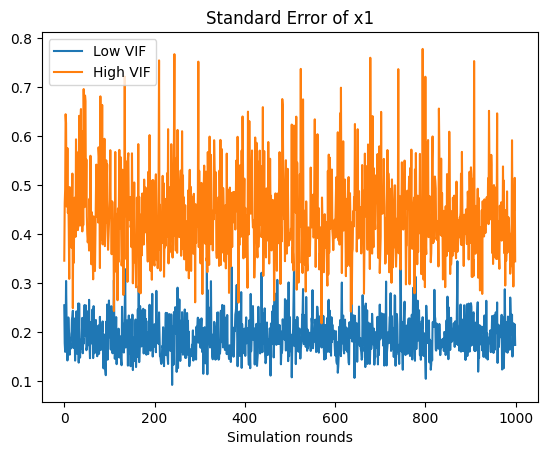
多重共線性が強いと推定値の分布は,真の値(\(\beta_1=\)
2.0)の周辺で低くなり左右に広がっている。推定値の精度が低下することを示している。\(\hat{\beta}_1\)の分散を計算してみよう。
np.var(b1hat_weak), np.var(b1hat_strong)
(0.038419493180949, 0.19607559558558993)
<Give it a try!>
以下のシミュレーションをおこない,違いは何か確認しなさい。
\(\hat{\beta}_0\)と\(\hat{\beta}_2\)の分布も図示しなさい。
nを変化させて違いを確かめなさい。Nを変化させて違いを確かめなさい。sim_multiを書き換えて\(\hat{\beta}_1\)と\(\hat{\beta}_2\)の標準誤差をプロットし問4のそれぞれの平均を計算しなさい。(ヒント:推定結果の属性bseを使う)
問4の答え:\(+\)を押すと答えが表示される。
問5の答え:\(+\)を押すと答えが表示される。
図を使ってチェック#
多重共線性は説明変数間の相関が高いと発生するが,ここでは相関度を図を使ってチェックする。色々な方法があるが,以下では2つ紹介する。
pandasの関数scatter_matrixを使う方法seabornというパッケージの関数pairplotを使う方法
pandasを使う方法#
まずコードの中でmatplotlibを明示的に導入せずにpandasのみを使い図示する方法を紹介する。こちらの方が簡単と感じるかもしれない。散布図を描いてみる。
wage1.plot.scatter('educ','wage')
pass
pandasのDataFrameやSeriesには図を作成するメソッドplot()が用意されている(裏ではmatplotlibが動いている)。例えば,wage1にあるeducのヒストグラムであれば次のコードで図示することができる。
wage1['educ'].plot(kind='hist')
もしくは
wage1['educ'].plot.hist()
またeducとwageの散布図は次のコードで描くことができる。
wage1.plot('educ','wage',kind='scatter')
もしくは
wage1.plot.scatter('educ','wage')
また1つのDataFrameにある複数列データを使い,複数の図を並べることも可能である。興味がある人はこのリンクを参照しよう。
変数の相関度をチェックするためにpandas.plottingのscatter_matrixを使う。このモジュールはDataFrameを引数とする。
scatter_matrix(wage1)
pass
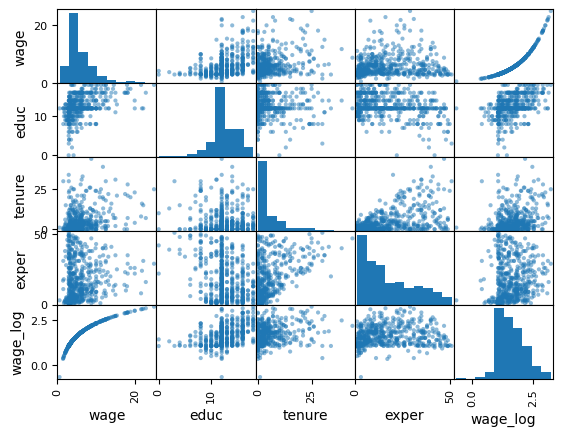
横軸と縦軸のラベルを確認すること。対角線上はそれぞれの変数のヒストグラム,対角線以外の図は縦横のペアの変数の散布図となっており,相関度をある程度目視で確認できる。
次に主なオプションとして2つを紹介する。
図の大きさは
figsize=(9, 6)で指定する。この例では9が横幅,6が縦幅である。diagonal='kde'を指定すると対角線上のヒストグラムをカーネル密度推定に変更できる。
scatter_matrix(wage1, figsize=(9, 6), diagonal='kde')
pass
次に相関係数を簡単に計算する方法を紹介する。DataFrameのメソッドcorr()を使うと変数の相関係数をDataFrameとして返す。
mat = wage1.corr()
mat
| wage | educ | tenure | exper | wage_log | |
|---|---|---|---|---|---|
| wage | 1.000000 | 0.405903 | 0.346890 | 0.112903 | 0.937062 |
| educ | 0.405903 | 1.000000 | -0.056173 | -0.299542 | 0.431053 |
| tenure | 0.346890 | -0.056173 | 1.000000 | 0.499291 | 0.325538 |
| exper | 0.112903 | -0.299542 | 0.499291 | 1.000000 | 0.111373 |
| wage_log | 0.937062 | 0.431053 | 0.325538 | 0.111373 | 1.000000 |
上の図と相関係数の値を見比べて,概ねどのような関係にあるのかを確かめよう。
seabornを使う方法#
seabornというパッケージを使うとより「見栄えがする」図を描くことができる。seabornについてはこのリンクを参照しよう。seabornはsnsとしてインポートするのが慣例である。
まず上でDataFrameのメソッドcorr()を使い変数の相関係数を計算したが,seabornのheatmap()関数を使うと相関係数を色に変換してより見やすい表示となる。
sns.heatmap(mat, vmin=-1, annot=True, cmap='coolwarm')
pass
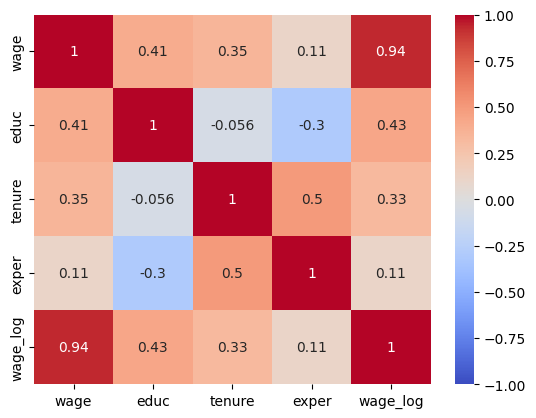
赤はプラス,青はマイナスを示し,色の濃淡は絶対値に連動している。ここで使った3つのオプション(設定しなくても良い)の説明する。
vmin:右の縦長の棒は表示される範囲を示すが,その最低値を-1にする(デフォルトは自動で設定)最高値を設定する
vmaxもあるが,.corr()の対角成分は1なので設定する必要はない。
annotは相関係数を表示する(デフォルトはFalse)cmapは色を設定する(デフォルトはNone)
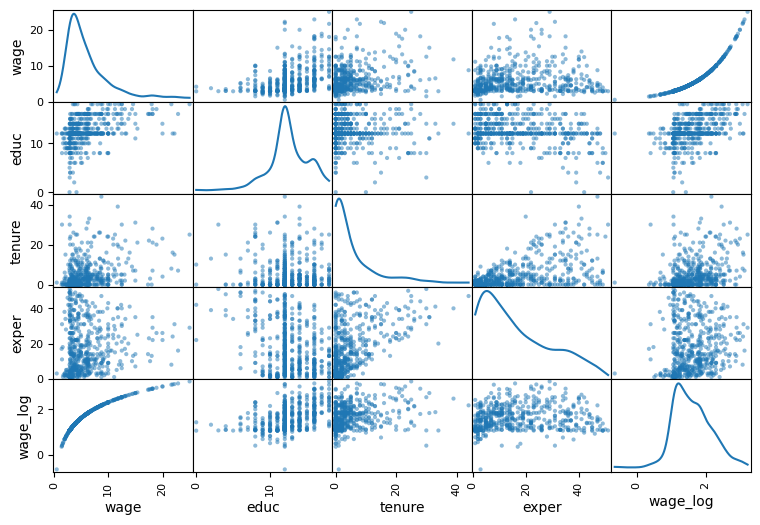
seabornにはmatplotlibの相関度をチェックするscatter_matrix関数に対応するpairplotがあり,より使い勝手が良いと感じるかもしれない。
sns.pairplot(wage1, height=1.5, aspect=1.3)
pass
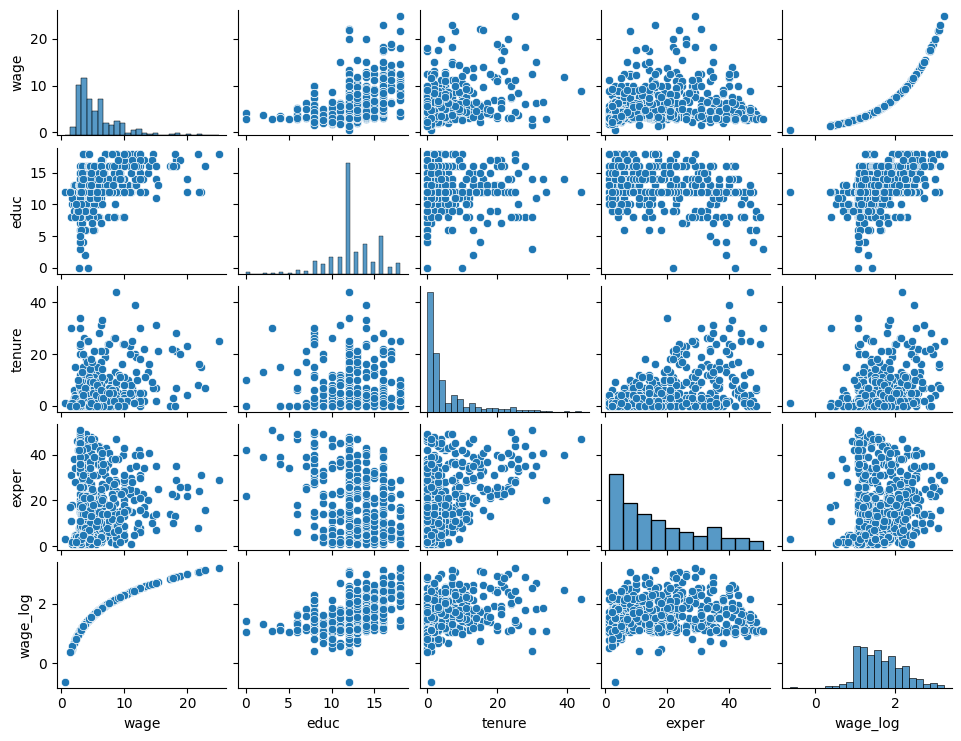
図の解釈はpandasの場合と同じである。
pairplot()の主な引数:
それぞれの図(ファセット)のサイズ
heightは高さを指定横幅は
aspect\(\times\)heightで設定する。
対角線上のヒストグラムをカーネル密度推定に変更する場合は
diag_kind=kdeと指定する。kind='reg'を追加すると,散布図に回帰直線が追加され相関度の確認がより簡単になる。
seabornの回帰分析に関係するプロットについてはこのリンクが役立つだろう。