Pythonで学ぶ入門計量経済学#
本サイトに関するコメント等はGitHubのDiscussionsもしくはharuyama@econ.kobe-u.ac.jpにご連絡ください。
姉妹サイト1:「Pythonで学ぶマクロ経済学 (中級+レベル)」 🚀
姉妹サイト2:「経済学のためのPython入門」 🐍
はじめに#
「なぜプログラミング?」文系の経済学の学生が理系のプログラミングを学ぶとなると,まず頭に浮かぶ質問かも知れない。過去にも同じような質問を問うた経済学部の卒業生は多くいると思われる。例えば,Excelのようなスプレッドシートのソフトは1980年代からあり,当時の大学生も使い方を学ぶ際「なぜ?」と思ったことだろう。しかし今ではWord,Excel,PowerPointの使い方は,大学卒業生にとって当たり前のスキルになっている。同じように,AI(人工知能)やビッグデータが注目を集める社会では,ある程度のプログラミング能力も経済学部卒業生にとって当たり前のスキルになると予想される。実際,文系出身でプログラミングとは縁のなかったある大手新聞社の記者の話では,社内でPythonの研修を受けており,仕事に活かすことが期待されているという。また,プログラミングを学ぶ重要性を象徴するかのように,2020年度からは小学校でプログラミング的思考を育成する学習指導要領が実施され,中学校では2021年度から,高校では2022年度からプログラミング授業が必修化された。また2025年の大学入学共通テストからはプログラミングの科目である「情報I」が追加される。このようにプログラミングのスキルの重要性は益々大きくなると思われる。
「なぜPython?」プログラミング言語は無数に存在し,それぞれ様々な特徴があり,お互いに影響し合い進化している。その過程で,広く使われ出す言語もあれば廃れていく言語もある。その中でPythonは,近年注目を集める言語となっている。それを示す相対的な人気指標としてStack Overflow Trendsがある。
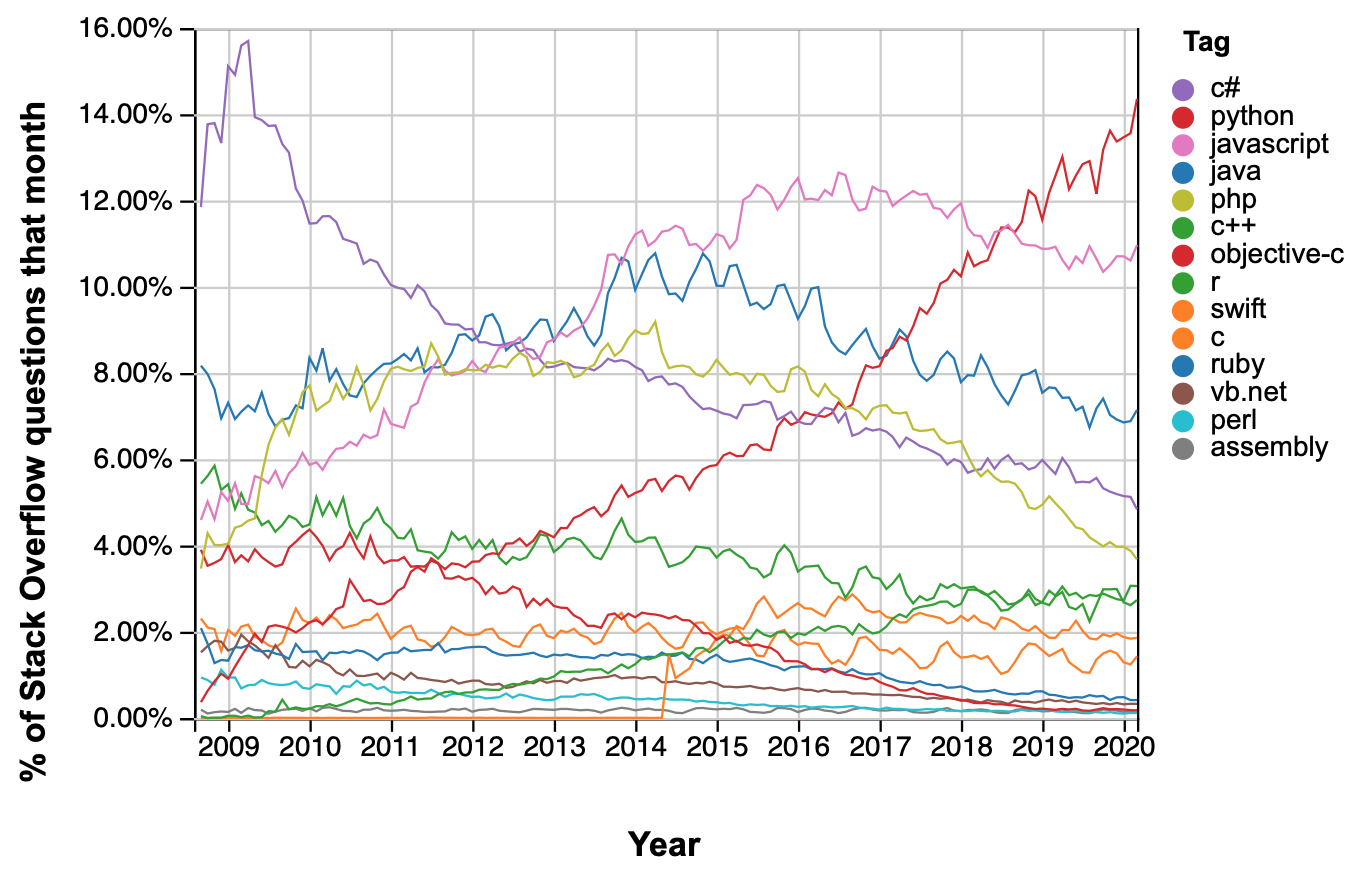
Fig. 1 Stack Overflow Trends#
Stack Overflowとは(日本語版はこちら),プログラミングに関する質問をすると参加者が回答するフォーラムであり,質の高い回答で定評があるサイトである。その英語版で,ある言語に関する質問が何%を占めるのかを示しているのがFig. 1である。2012年頃からPythonは急上昇しているが(右上がりの赤色の線),過去5年間でみると下降トレンドの言語が多い印象である。もう一つの指標として2020 Kaggle Machine Learning & Data Science Surveyを紹介する。Google合同会社の子会社であるKaggleは,データサイエンスや機械学習などに関連する課題を解決するためのコンテストがおこなわれる有名なオンライン・コミュニティであり,課題には賞金が設定され世界中からの参加者が切磋琢磨して競争する。2020年におこなわれたKaggle参加者へのアンケートの中に「データサイエンティストを目指し,初めてプログラミングを学ぶ人にどの言語を薦めますか?」の質問があり,17,740の回答中(重複回答含む)80%がPythonを選んでいる。Pythonの独り勝ち状態である(他の言語を含めた図はこちらを参照)。
では,Pythonの人気はどこにあるのか?まず最初の理由は無料ということである。経済学研究でよく使われる数十万円するソフトと比べると,その人気の理由は理解できる。しかし計量経済学で広く使われるRを含めて他の多くの言語も無料であり,それだけが理由ではない。人気の第2の理由は,汎用性である。Pythonはデータ分析や科学的数値計算だけではなく,ゲーム(ゲーム理論ではない),画像処理や顔認識にも使われている。またPCやスマートフォンの様々な作業の自動化に使うことも可能なのである。第3の理由は,学習コストが比較的に低いことである。Pythonのコードは英語を読む・書く感覚と近いため,他の言語と比較して可読性の高さが大きな特徴である(日本語にも近い点もある)。もちろん,Pythonの文法や基本的な関数を覚える必要があるが,相対的に最も初心者に易しい言語と言われる程である。他にも理由はあるが,PythonはIT産業だけではなく金融・コンサルティング・保険・医療などの幅広い分野で使われており,データ分析の重要性が増すごとにより多くの産業で使われると思われる。
Pythonは経済学でどれ程使われているのだろうか。残念ながらデータはないが,私の個人的な印象では,数値計算に優れているMatlab(有料)やOctave(無料),計量経済学ではR(無料)やStata(有料)が広く使われているようであり,その中でPythonは比較的にマイナーであった。しかし近年それが変わる気配がある。2011年にノーベル経済学賞を受賞したThomas J. SargentとJohn Stachurskiが始めたQuantEconでは,Pythonと今後有望視されるJuliaのパッケージが公開され,高額な有料ソフトであるMatlabでできることが可能になっている。また講義ノートや様々なコードも公開され,特に若い研究者は大きな影響を受けるのではないかと予想される。更には,経済学関連分野のファイナンスやデータ・サイエンス(例えば,機械学習)の分野ではPythonは広く使われている。
まず経済学部生にとっての関心事は、Pythonを学ぶ意義はどこにあるのかということだろう。IT関連企業への就職を考えていない学生であれば、なおさらそうであろう。実際、図1のデータはディベロッパーや様々な学問・業種の人々の行動を反映しており,経済学に携わる人の中での人気を表している訳ではない。しかし経済学部の大多数の卒業生は幅広い産業で働くことになる。社会全体で注目され,今後より多くの産業で使われることが予測される言語を学ぶことは有意義ではないだろうか。
本サイトの目的は基本的なPythonの使い方を学び,入門レベルの計量経済学をPythonを使って学ぶことである。換言すると,計量経済学を通してPythonの使い方を学ぶことである。本書を通して学ぶPythonの知識は,他分野への応用に大いに役立つと期待される。またPythonを使い推定だけではなくシミュレーションもおこなうため,計量経済学の教科書で学ぶ推定量の性質などを直に感じ取り,計量経済学の復習にも役立つであろう。第1部では,Pythonの基礎を学び,第2部では計量経済分析にPythonをどのように使うかを解説する。第3部では番外編として,関連するトピックに言及する。
参考書#
本サイトでは世界的に有名な学部レベルの教科書であるWooldridge (2019)を参考にしている。またこの本で扱われるデータを使い推定をおこなう。
Introductory Econometrics: A Modern Approach, 7th ed, 2019, J.M. Wooldridge
和訳がないのが不思議なくらい有名な教科書なので,英語の勉強を兼ねて是非読んで欲しい教科書である。
本サイトで使うPythonとパッケージのバージョン#
import gapminder, linearmodels, lmdiag, matplotlib, numba, numpy, pandas, py4macro, py4etrics, scipy, statsmodels, wooldridge
from platform import python_version
packages = ['Python','gapminder','linearmodels', 'lmdiag','matplotlib', 'numba', 'numpy','pandas', 'py4macro', 'py4etrics', 'scipy', 'statsmodels', 'wooldridge']
versions = [python_version(),gapminder.__version__, linearmodels.__version__, '0.3.7', matplotlib.__version__, numba.__version__, numpy.__version__, pandas.__version__, py4macro.__version__, py4etrics.__version__, scipy.__version__, statsmodels.__version__, wooldridge.__version__]
for pack, ver in zip(packages, versions):
print('{0:14}{1}'.format(pack,ver))
/Library/Frameworks/Python.framework/Versions/3.12/lib/python3.12/site-packages/gapminder/data.py:1: UserWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html. The pkg_resources package is slated for removal as early as 2025-11-30. Refrain from using this package or pin to Setuptools<81.
import pkg_resources
Python 3.12.10
gapminder 0.1
linearmodels 6.1
lmdiag 0.3.7
matplotlib 3.10.6
numba 0.62.0
numpy 1.26.4
pandas 2.3.2
py4macro 0.8.15
py4etrics 0.1.9
scipy 1.16.2
statsmodels 0.14.5
wooldridge 0.4.5
おまけ1#
神戸大学経済経営学会が出版した「経済学の歩き方」は初学者を対象として経済学に関する59のトピックを厳選し解説している。私が執筆した章「Pythonによるマクロ経済分析」はGitHub上で公開している。原稿で使ったコードとデータ作成に使ったコードも公開しているので,Pythonで何ができるかを手っ取り早く知りたい人にはオススメかも知れない。
おまけ2#
これをPythonコードで書いてみた。
Fig. 2 正規分布と超常分布#
import numpy as np
from scipy.stats import norm
import matplotlib.pyplot as plt
xx = np.linspace(-2.75,2.75,100)
plt.xkcd()
fig = plt.figure(figsize=(10,4))
ax1 = fig.add_subplot(1,2,1)
ax2 = fig.add_subplot(1,2,2,sharey=ax1)
ax1.plot(xx, norm.pdf(xx,scale=1), 'k')
ax1.set_title('Normal Distribution', size=25)
ax2.plot(xx, norm.pdf(xx,scale=1), 'k')
ax2.scatter(-0.4, 0.28, s=300, linewidth=2.5, facecolors='k', edgecolors='k')
ax2.scatter(0.4, 0.28, s=300, linewidth=2.5, facecolors='k', edgecolors='k')
ax2.plot(xx,-0.02*np.cos(3*xx), 'k')
ax2.set_title('Paranormal Distribution', size=25)
plt.show()